보청기 스타트업에서 일하는 임베디드 DSP 엔지니어는 보청기로 들어오는 소리를 마이크로부터 데이터로 받아, 보드로 들어오는 아날로그 신호를 칼리브레이션하고, 이를 원하는 소리로 연산하여 스피커로 내보내는 개발입니다. 에어팟 프로나 갤럭시 버즈에서 보이는 Equalizer, 음량조절, 외부소리 듣기, 노이즈캔슬링과 같은 기능이 개발해야 하는 일이었습니다. 특히 다른 시스템보다 훨씬 하드웨어 스펙이 arm cortex-m0와 같이 낮으면서, 배터리 용량도 중요하기 때문에 알고리즘뿐 아니라 이를 최적화하여 에너지 소모량을 줄이는 것 또한 중요했습니다.
Prologue
보청기에서 여러 알고리즘 중 중요하게 고려되는 것은 사람의 목소리를 선명하면서 너무 날카롭거나 불편하지 않게 증폭시키는 것입니다. 이를 위한 연구로, 소음제거(Noise Reduction) 연구가 있습니다. 이는 Speech Enhancement(음질 개선)이나 Source Separation(음원 분리) 기술을 이용하곤 합니다. 이 개발을 맡아, 연구 방향성은 크게 두 갈래로 나눌 수 있었습니다.
1. ML Method
- Magnitude spectrum
spectral masking
spectral mapping
- Complex domain
- Time domian
- Multi-stage
- Feature augmentation
- Audio-Visual SE
- Netword design
Filter design
Fusion technique
Attention
U-Net
GAN
Auto-Encoder
Hybrid SE
SepFormer(Transformer)
- Phase reconstruction
- Learning strategy
Loss function
Multi-task learning
Curriculum learning
Transfer learning
- Model Compression
2. Classical
- Wiener filter
- Kalman filter
- minimum variance distortionless response (MVDR) beamformer
위 처럼 기존에 Classical Statistical method을 이용할 것인가, 아니면 Machine Learning 을 이용할 것인가로 나뉩니다. 당시 저는 ML, AI, DSP에 대한 knowledge와, DSP 어플리케이션(e.g. all types of digital filters, equalizer) 을 개발할 수 있었고, 회로를 읽을 수 있었습니다. AI로 연구방향을 하자고 생각하니, 회사내에 인프라나 관련 연구를 하는 동료가 없거니와, 결국 최종적인 형태로 AI를 TinyML로써 Edge device에 올려야 하는데, 이를 연구하는 커뮤니티가 활발하지 않았습니다. 커뮤니티 중 제일 컸던 tflite-micro 에서도 아직 under-develop된 경우가 많아서 ‘과연 현실 가능성이 있는 연구이자 보청기에서 효과적인 연구인가?’를 우선 증명했어야 했습니다(현재는 Torch 2.0 이후로 Torch에서도 해당 연구가 활발하게 이뤄지고 있습니다). 조사하던 와중, 파트너로 협업하는 회사에서 아직 Neural Network에 대해 기본적인 기능만 개발돼 있고, Bose에서도 보청기를 위해 연구된 Speech Enhancement 연구가 2020년에 발표돼 LSTM을 경량화해서 STM32F746VE에 올린 연구만 발표됐었습니다. STMF7 시리즈는 armv7hf로 M시리즈 중에 제일 성능이 좋은 칩이고 Discovery 보드로 기본적인 어플리케이션에 연구하기 좋은 환경입니다. 이는 즉, 연구에 대한 가능성이 있음을 보여주는 단서라고 생각했고, 회로를 읽을 줄 아는 부분에 있어서 하드웨어와 밀접한 연관이 있는 연구가 더 메리트가 있다고 생각했습니다. 그래서 보청기의 소음제거를 위해 Speech Enhancement과 TinyML 연구를 시작했습니다.
Speech Enhancement and Source Separation
Speech Enhancement 연구는 크게 세 가지 데이터, 모델, 그리고 평가방법을 고민합니다(Source Separation을 언급해놓은 것은 이를 이용해서 Speech Enhancement를 개발하기도 해서 입니다).
- Which dataset we can use?
- Which model backbone we can use?
- How can we evaluate the model(+Loss function)?
1. Which dataset we can use?
데이터 셋은 크게 두 가지로 타겟 소리와 소음으로 나뉩니다. 주로 타겟 소리와 소음을 Mixture한 소리와 타겟소리를 가지고 모델을 학습시키고 Mixture힌 소리에서 타겟소리만 얼만큼 추출할 수 있는지로 모델을 평가합니다. 음원에 관련된 데이터셋은 이 링크에 따로 정리를 해놨습니다.
여기서 비지니스에서 현실적인 선택지는 별로 없습니다. 우선 사내에서 관련해 데이터를 수집하고 있지 못하고, 오픈 데이터셋으로 기업에게 라이센스가 오픈인 경우는 VoiceBank-DEMAND 이라는 데이터 셋밖에 없었기 때문입니다. VoiceBank-DEMAND에 대해 조금 더 설명하자면, 이 데이터셋은 VoiceBank(VCTK)라는 사람 목소리 데이터셋에 DEMAND라는 소음 데이터셋을 합친 데이터입니다 (더 자세한 내용은 이 곳에 있습니다).
그리고 다른 방법은 Challenge에 참여해 데이터로 모델을 평가하는 방법입니다. 소음 제거로는 Microsoft DNS Challenge나 Clarity Challenge가 있었습니다. Microsoft의 경우는 늦게 발견해서 이용하지 못했으나, 데이터 셋이 상대적으로 워낙 큰 편에 속했습니다. 그리고 Clarity Challenge의 경우는 Hearing Test 데이터, 소음과 목소리가 합쳐진 데이터, 목소리 데이터, 그리고 데이터를 수집한 시나리오를 제공해줘, 결론적으로 저는 Clarity Challenge + VoiceBankDEMAND, 두 가지 데이터 셋 조합으로 데이터를 결정합니다.
2. Which model backbone we can use?
모델은 입력 데이터 형태에 따라 크게 Time domain과 Frequency domain 방향으로 나뉩니다. 사실상 Time domain도 Spectral Time Frequency domain를 CNN 계열 네트워크로 대체하긴 합니다. 제가 연구를 했던 당시(2022.03)는 Frequency domain에서 연구가 압도적으로 많았고, Time domain에서 유명한 모델인 WavUnet, ConvTasNet이 있었습니다. 다른 고려사항은 제가 타겟하는 하드웨어 플랫폼이 저사양 하드웨어인 점을 고려해 Bose의 연구를 레퍼런스 삼아 모델 크기를 1MB를 기준으로 가능성을 가늠했습니다.
후보는 기본적인 Neural Network(DNN, CNN, RNN), Bose 연구를 벤치마킹할 수 있는 RNN계열(RNN, LSTM, GRU), Frequency domain에서 대표적으로 알려진 CRN(Complex Recurrent Network), DCCRN(Deep Complex Convolution Recurrent Network), Time domain에서 대표적인 WavUnet, ConvTasNet, 그리고 아직 실험중인 Transformer형태의 Sepformer 까지 총 10가지 모델을 평가했습니다.
- DNN(Deep Neural Network)
- RNN(Recurrent Neural Network)
- CRN(Convolutional Recurrent Network)
- DCCRN(Deep Complex Convolutional Recurrent Network)
- Unet
- WavUnet
- DCUnet
- Demucs-v2
- ConvTasNet
- Sepformer
해당 모델들에 대한 자세한 코드는 해당 링크에서 확인 가능합니다. 참고로 실시간 오디오 스트리밍으로 테스트해보고 싶으시면 Denoiser라는 Facebook에서 연구하는 플랫폼이 있습니다. 이를 이용하면 노트북에 마이크 스트림을 실시간으로 모델이 처리한 결과를 이어폰으로 들어 볼 수 있습니다.
3. How can we evalueate the model?
모델의 성능을 평가할 수 있는 방법은 쉽게 생각할 수 있는 방법은 사람이 듣는 것 입니다. 하지만 음원마다 일일이 들어보기는 현실적으로 어려울 뿐 아니라, 고도난청까지 가는 음원을 듣는 것은 일반인에게 힘들 것입니다. 학계에서는 Speech enhancement task에서 Top K 처럼 연구자들은 몇 가지 Metric을 내놓습니다. 그 중 대표적인 것으로 STOI(Short-Time Objective Intelligibility), PESQ(Perceptual Evaluation of Speech Quality), SDR(Signal Distortion Ratio), SI-SDR(Scale-Invariant Signal Distortion Ratio)이 있습니다. 저는 이 중에 가장 직관적이고 쉽게 연산할 수 있는 SI-SDR을 지표로하고 나머지 Metric들을 metadata로 삼았습니다 (관련해서 자세한 설명은 여기에 있습니다).
그리고 이 테스트에 loss function으로는 모델의 출력이 타겟의 소리에 time domain이나 frequency domain에서 값이 유사하게 만들어 가는 것으로 합니다. 다만, frequency domain일 경우는 amplitude 만을 고려할 수도 있고, phase도 함께 고려하는 방법도 있습니다. 또한 SI-SDR와 같은 metric을 이용해 loss function으로 하는 실험도 함께 진행했습니다. 다만 Source separation의 경우에는 여러 명의 화자를 타겟으로 하는 경우도 있어, 나오는 모델 결과를 타겟 화자 수와 일치 시켰습니다. 이 경우, loss function에서 모델 결과와 타겟 음원를 화자 수만큼 Permutation을 돌려 loss가 최대인 경우로 맞췄습니다.
Epilogue : Result
앞선 실험들에 대한 결과는 여기서 보실 수 있습니다. VoiceBank-DEMAND내에서 SI-SDR는 모델을 사용했던 논문에서 나오는 수치까지 달성할 수 있었고, 해당 실험을 진행하면서 Clarity Challenge에서 Top 5도 들 수 있었습니다. 하지만, 정해진 데이터셋내에서 특정음원에 대해서는 제대로 음원이 선명하게 나오지 못했습니다. 모델의 성능에 초점을 맞춰 더 디벨롭 시키는 방향도 있지만 우선은 모델이 Edge device에서 돌아가는 파이프 라인이 우선적이라고 진행하기로 결정하고 다음 단계로 넘어갔습니다.
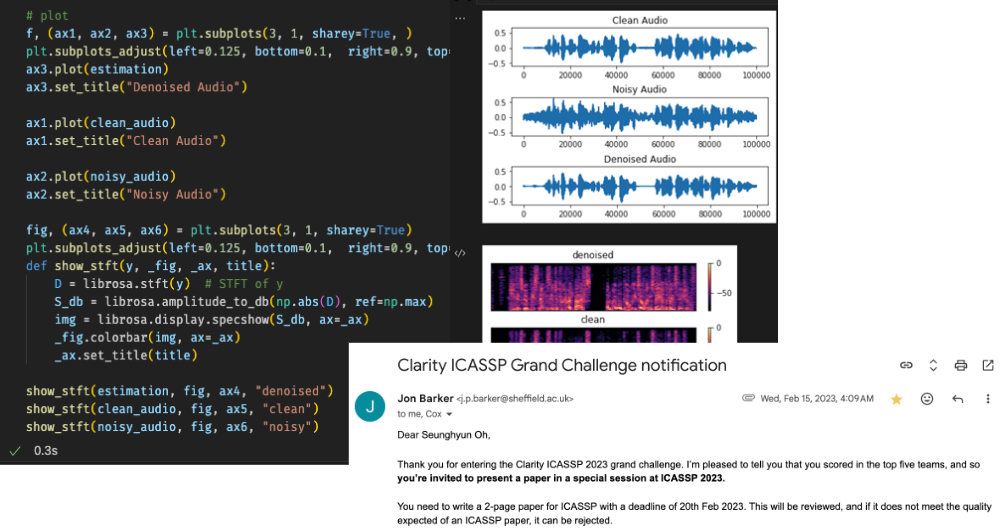
Top five in Clarity ICASSP Grand Challenge
이 자료가 관련 연구를 하시는 분들께 도움이 되길 바라며, 저는 Part 2. Platform for microphone streaming 으로 다시 돌아오겠습니다.
Reference
1. ML models Platform
- https://github.com/asteroid-team/asteroid
- https://github.com/speechbrain/speechbrain
- https://github.com/facebookresearch/demucs
2. Other Research for speech enhancment methods
- https://github.com/Wenzhe-Liu/awesome-speech-enhancement
- https://github.com/nanahou/Awesome-Speech-Enhancement
- https://ccrma.stanford.edu/~njb/teaching/sstutorial/part1.pdf
- https://www.microsoft.com/en-us/research/wp-content/uploads/2016/07/interspeech-tutorial-2015-lideng-sept6a.pdf
- https://www.citi.sinica.edu.tw/papers/yu.tsao/7463-F.pdf