개발자분들과 이야기 나누다가 사이드프로젝트 이야기를 나눴던 적이 있었다. “저는 지금 무선이어폰을 만들고 있어요.” 내가 하는 프로젝트를 잠깐 언급하자 한 분이 “그게 가능한건가요?” 라고 되물어주셨었다. 어… 그건 짧게 답하기 어려운 질문이었다.
이어폰을 만드는 프로젝트를 마무리 짓는 단계에 있습니다. 마침 글또 10기, 대망의 마지막 기수도 시작했다 싶어 시기가 비슷하게 맞아 떨어져 지금까지 해 온 과정을 공유드리려고 합니다 (혹시 이어폰 형태의 DIY를 만들고 싶으신 분이라면 바로 Open-earable 에 가셔서 튜토리얼을 따라하셔도 좋습니다. 참고로 스피커(BA)는 PIN으로만 나와있습니다).

Hearing aid in Olive Union
저는 이 시절에 보청기를 만드는 신호처리(DSP) 개발자였습니다. 모든 사람들이 보청기를 쉽게 그리고 정교하게 자신에게 맞는 보청기를 접할 수 있도록 무선이어폰 형태로 제품 양산부터 펀딩까지 모든 과정을 거치는 스타트업에서 일하고 있었습니다. 그 중에서 작은 한 부분으로 음성 증폭, 소음 제거 그리고 보청기와 관련된 다양한 어플리케이션을 개발하고 있었습니다. 개발 분위기가 워낙 자유워로웠던 환경이라 처음부터 제가 해야하는 기능을 스스로 찾아나서야 했었습니다. 다행히 주변 동료들이 모두가 디스커션을 환영하는 분위기여서 자신있게 여러 기능들을 동료들에게 제안할 수 있었고, 그들이 만든 기능들에 대해서 의구심을 가지는 부분도 더 적극적으로 물어볼 수 있었습니다.
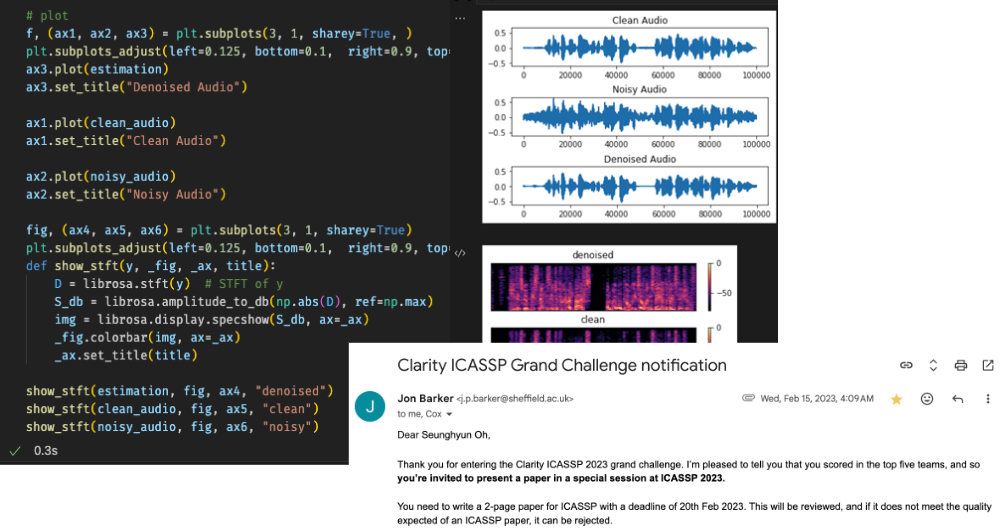
Top five in Clarity ICASSP Grand Challenge
이 시절, AI에 관심이 많았습니다. 사람의 근원에 대한 호기심으로 대학원 시절 전공외에 신경과학, 심리학이나 언어학과 같은 과목들을 탐구하다가, 지금까지 가져온 전공(참고로 제 전공은 고속 인터페이스 아날로그 회로 설계입니다)을 더 살릴 수 있는 방법을 고민했었습니다. 대학원 졸업 후, 고민 끝에 내린 결론은 안정적인 직장을 마다하고 도전적으로 디지털 신호처리라는 분야에 방향을 조금 돌렸습니다. 신입으로 들어가서 회사 업무에 적응하면서, 틈나는 대로 인공지능에 대해서 공부하면서 소리도메인에서 인공지능을 활용해서 문제를 해결하고 있는 여러 기업들도 알아갔었습니다. 그 와중에 발견한 분야가 Speech Enhancement(음질 개선)과 Source Separation(음원 분리)였습니다(참고로 가장 편리하게 이용가능한 대표적인 오픈소스는 Facebook에 Denoiser가 있습니다). 약간 타이밍이 잘 맞았던게, 이 즈음 상대 협력업체에서도 DNN을 이용한 어플리케이션으로 소음제거를 옵션으로 공개하기도 했었어서, 지금 업무에 적용하면 괜찮겠다 싶어서 관련 연구를 시작헀습니다. 데이터셋, 모델 그리고 성능 평가 방법을 하나 두개씩 알아가고, Bose에서 연구한 Speech Enhancement 논문을 벤치마킹 삼아서 디바이스에 포팅하려고 시도해봤지만, 현재 사용하는 개발보드에서 지원하지 않는 기능을 위해 상대 협력사에게 추가로 요청하려면 우선 CTO부터 설득해야하는, 난관이 겹겹이 있었습니다. 무료로 오픈한 하나의 데이터셋과 Clarity Challenge와 같은 보청기를 위한 음질개선 챌린지에서 모델을 개발하고 운이 좋게 순위권에 들기도 했지만, 개발한 모델을 가지고 현재 개발중인 개발보드에는 적용이 가능할 지 가늠하기가 어려웠습니다. 더군다나 이 시절에는 TinyML에 대한 연구도, Tflite-Micro에서 테스트 가능한 보드도 적었고, 몇 안되는 다른 동료들도 “그게 불가능해.” 했지만 혼자서 관련 연구에 시간을 쏟았었죠.
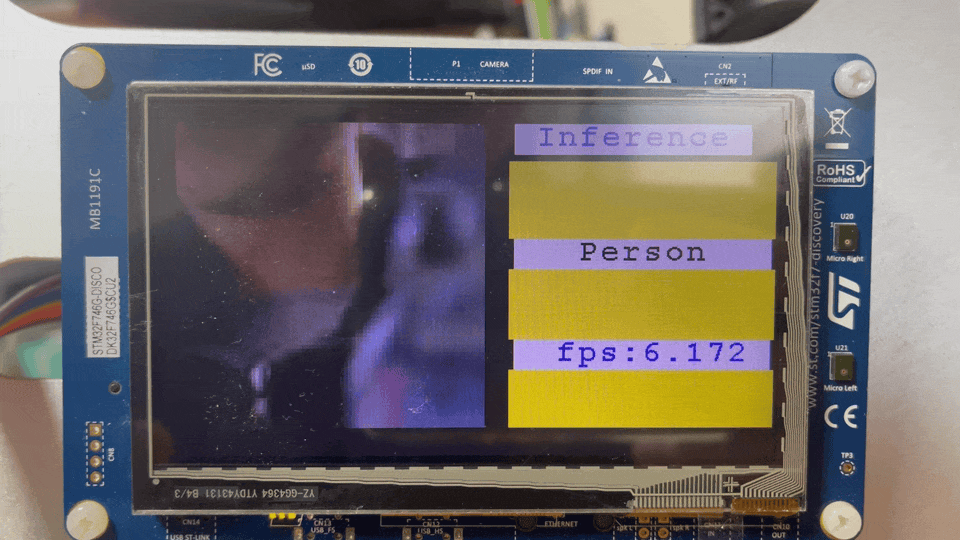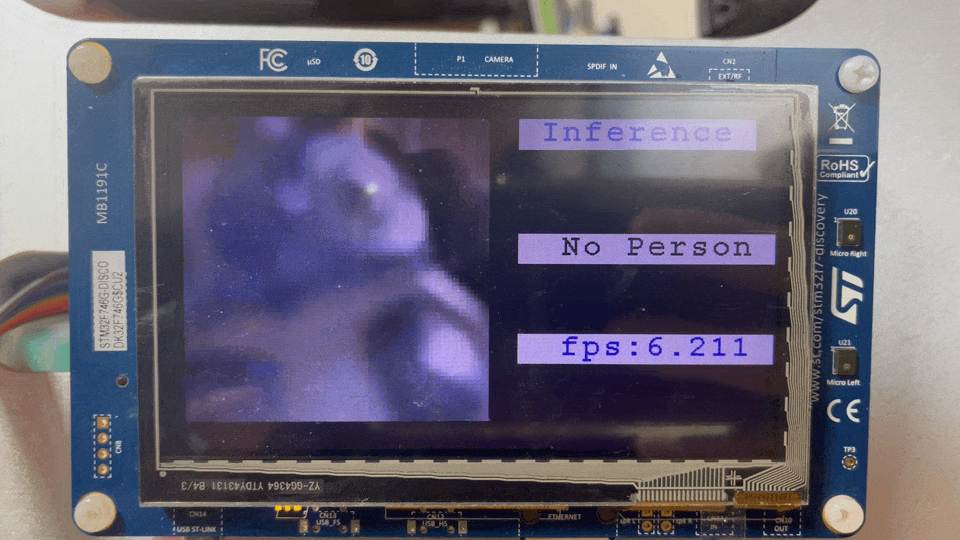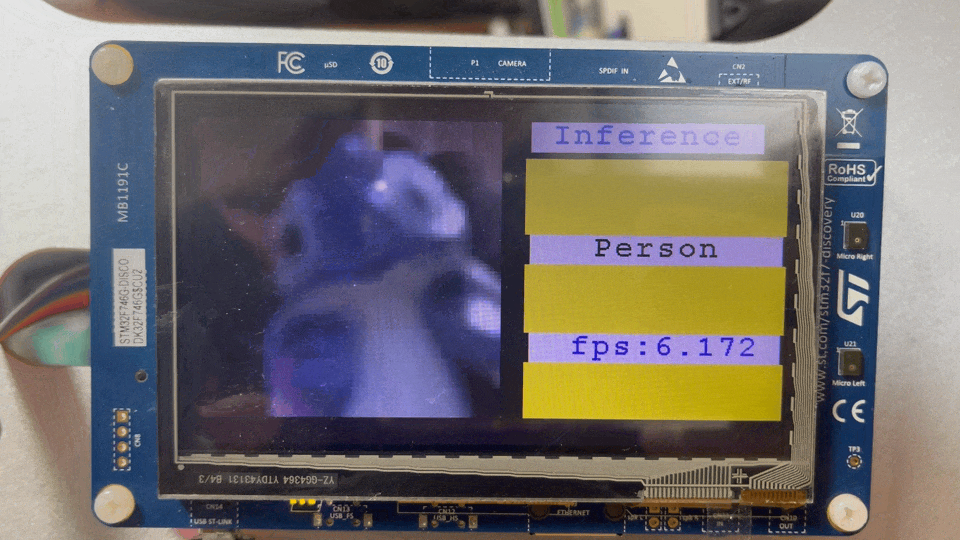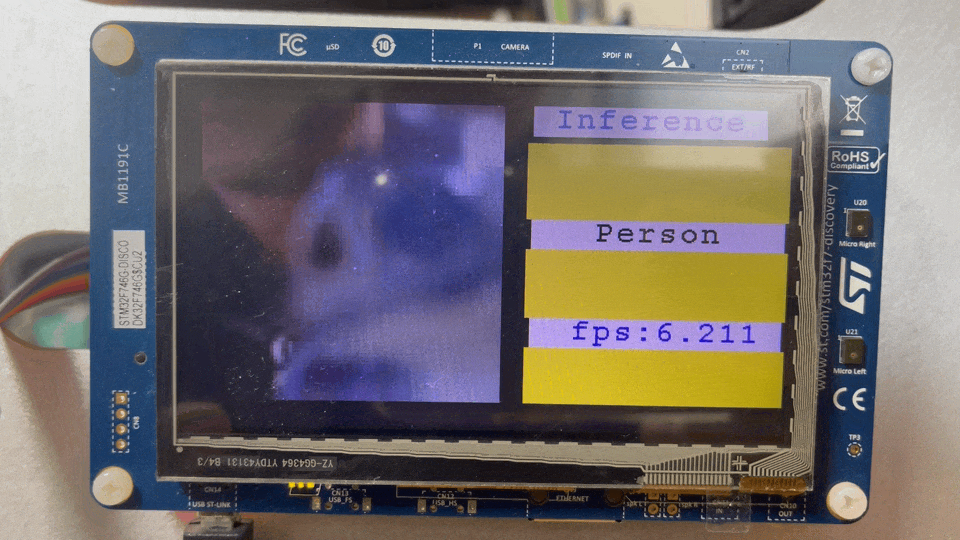
Research TinyML in STM32F746G
엎친데 덮친격으로 동료들은 하나 둘씩 떠나갈 무렵, 저는 여전히 Bose의 연구를 벤치마킹을 하려고 시도했습니다. 결국, 혼자서는 업무와 동시에 이 개발을 하는 건 무리겠다고 생각했습니다. 다행히 CTO님이 개발이 용이한 STM32F746보드에서 데모식으로 가자는 제 의견을 받아들여, 관련해서 모델을 올릴 수 있도록 마이크 스트리밍 어플리케이션(e.g. 에어팟의 Transparency 모드)와 AI 모델관련 라이브러리를 포팅해놓고 이직했습니다. 개발보드에서 오디오 코덱이나 드라이버단을 커스터마이징도 해보고, 실제로 드라이버를 통해 오디오 버퍼를 가져오면서 오디오 스트리밍에 대한 이해가 높아지는 경험이었습니다.
하지만 여기까지만 해도 이어폰을 만들 것이라고 지금의 저도 생각치 못할 겁니다. 여기서 제가 관심을 가지기 시작한 연구은 모델을 돌리기 위한 안정적인 실험환경(플랫폼)과 모델이 적절한 성능을 유지하면서 어디까지 작은 리소스내에서 돌아갈 수 있을까에 대해 더욱 매력을 느꼈습니다. 이미 연구가 진행되고 있는 분들을 많이 찾지 못해 얼만큼 성장할 있을 지 가늠은 어려웠지만, AI모델에 들어가는 개발비용이 커지는 추세에서 이런 연구는 더 매력적이라고 생각했었죠. 하지만 실험할 수 있는 플랫폼으로써 디바이스를 만드는 것은 현 상황으로는 조금 무리가 있었습니다. 국내에서 활발한 커뮤니티는 주로 휴대폰과 웹을 이용한 서비스가 다수였고, 최근(2024)들어 IoT가 흐름으로 오면서 하나 둘씩 관심이 있으신 분들이 생기셨지만 이직할 당시만해도 이 분야에 대해서 관심이 많은 사람이 적거나 업계로 들어오기 전에 포기한 글들을 자주 봤었습니다. 그래도 제품까지 만들어보고 싶었던 건 풀리지 않는 궁금증이 몇가지 있어서 였죠. 대표적으로 오디오 버퍼를 받을 떄마다 64 sample씩 전달해주곤 했었는데, “조금만 늘려주면 알고리즘이 수월해질텐데…” 라는 아쉬움, “도대체가 마이크로 데이터가 들어오면서부터 스피커로 나가면서까지 무슨 일이 있는데 그럴까?” 라는 호기심, 그리고 신호처리 알고리즘을 개발하면서 exponetial 계산과 같이 기본이 되는 연산을 개발보드의 instruction set으로 만들면서 다른 개발보드는 내가 경험한 개발보드와는 어떤 부분이 다를까? 와 같은 기대감과 같은 것들이 있었기에 그만두지는 않았습니다. 그렇게, 맡은 개발보드 세팅과 모델까지 전달드리고 저는 새로운 회사에 들어가서는 사이드프로젝트로 디바이스를 만들어 보기로 한겁니다.
두근두근 드디어 PCB 주문!
이직 후, 시간은 정신없이 지나갔습니다. 다시 이 사이드 프로젝트를 시작해야 겠다 싶었을 때 디바이스 형태를 조사하기 시작했을 때, 생각보다 github처럼 펌웨어나 회로도도 커뮤니티로 크게 활성화돼 있는 것이 신기했습니다. 특히나 PCB를 만들어 보시려고 하신 분들은 많이 접해보셨을 PCBway 나 JLCPCB 같은 회사에서도 다양하게 본인들이 만든 회로도를 오픈해놨었고 Smartwatch 쪽이 가장 많이 눈에 띄었습니다. 이 즈음 앞서 언급했던 University of Washiongton에서 ClearBuds나 Karlsruhe Institute of Technology에서 Open-earable이라는 무선이어폰를 하드웨어에서 펌웨어까지 오픈소스로 공개해놓은 것을 발견했을 때, 이어폰을 만들어볼 수 있겠다 확신이 들었습니다. 그리고, 시작했죠.
자, 이제 이러한 제품을 만들어보는데 조금이나마 다른 분들이 시간을 절약하실 수 있었으면 하고 하나씩 자세하게 이야기해보겠습니다.

Target open source project, Open-earable(Left) and current status(Right)
- Speech Enhancement & Source Separation
- Which dataset we can use?
- Which model backbone is popular and Why?
- How can we evaluate the model?
- Platform for microphone streaming
- Which manufacturer is popular?
- How to build up as a beginner
- Device for microphone streaming (feat. Earbud)
- Basic Schematic and PCB tutorial for beginner
- Which device and target goal is in open source?
- Which tool we can use?
- How to build up as a beginner