이전회사에서 Tensilica Processor IP로 HiFi DSP를 사용했었다. DSP는 신호처리를 위해 자체적인 병렬연산처리 Instruction이 있는 Processor인데, 배터리를 가지고 있는 임베디드 시스템상 알고리즘 마다 전력소모를 최소화하기 위해 MIPS나 FLOP 대신 MCPS(Million Cycles Per Second)와 MOPS(Millon Operations Per Second)를 Xtensa IDE에서 제공하는 프로파일링을 이용해서 최적화 작업을 하였다. 이 당시에는 DSP 알고리즘 자체를 최적화하면서 별 거 아닌 것 처럼 여겼지만, 실제로 제품 배터리를 총 5시간 중 30분이 늘어나는 것을 보고 Cache를 사용하는 것과 같이 C/C++ 언어 자체로 최적화하는 작업이 어떻게 이뤄지는지 궁금했었다. 그러던 찰나, TinyML에 관련한 강의를 듣던 와중에 궁금해 하던 최적화 기법 중에서도 TinyML을 위한 최적화와 그에 대한 예제를 직접 보드에서 볼 수 있어 정리해보았다.
1. Introduction of Microcontrollers
흔히 보는 ML과 TinyML의 차이는 어디에서 오는 걸까? 일반적으로 보는 컴퓨터와 달리, Microcontroller 혹은 MCU(Microcontroller Unit)는 최소한의 컴퓨팅 요소만 가지고 있는 집적회로를 말한다. 많이 알려진 제품군으로는 아두이노나 라즈베리파이에서부터 STMicroelectronics, Texas Instruments(TI), Microchip Technology, Nordic Semiconductor등 다양한 제품군이 있다.
이들은 아래 그림처럼 CPU부터 휘발성 메모리(e.g. SRAM), 비휘발성 메모리(e.g. ROM, Flash Memory), Serial input/output (e.g. UART), Peripherals (e.g. watchdog), ADC(Analog to Ditital Converter), DAC(Digital to Analog Converter)등을 가지고 있는데,
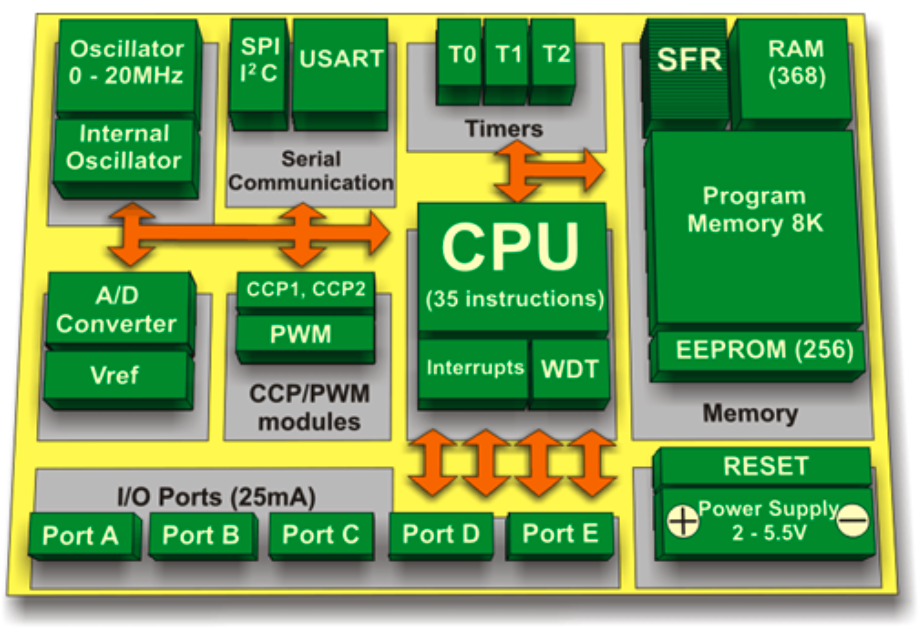
Reference. MIT-TinyML-lecture17-TinyEngine in https://efficientml.ai
이들의 메모리 구조를 보면 확연히 컴퓨터와는 메모리 크기가 다른 것을 볼 수 있다. 그렇기에 무엇보다 작고 소중한 메모리를 더 많이 활용하기 위해 Cache가 중심으로 기법들을 설명할 것이다. 먼저 어떤 부분이 문제가 될 수 있을까? 알고리즘 중에서도 Neural Network를 이용하기 위해 어떤 점이 허들이 될 수 있을까?

Reference. MIT-TinyML-lecture17-TinyEngine in https://efficientml.ai
2. Neural Networks on Microcontrollers
첫 번째는 적은 메모리, 그 중에서도 SRAM을 지적하고 있다. 기존에 적으면 8GB, 크면 64GB가 되는 개인용 컴퓨터의 DRAM에서는 걱정하지 않았던 부분이 Microcontroller에서는 320kB까지 줄어들 수 있기에 문제가 될 수 있다.
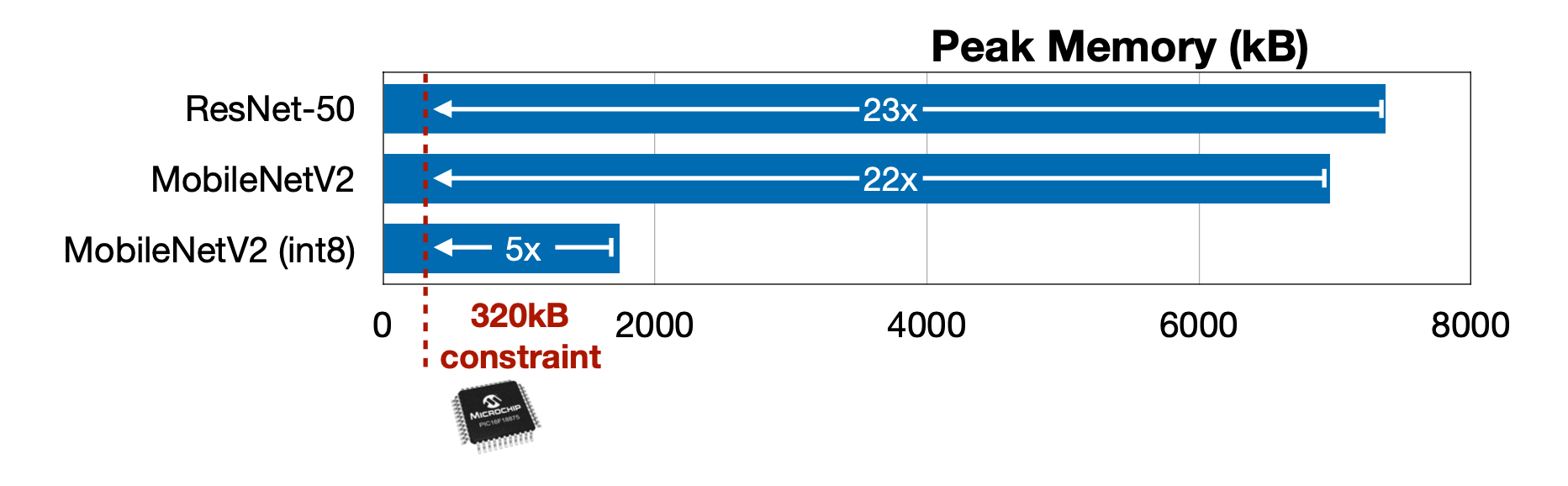
Reference. MIT-TinyML-lecture17-TinyEngine in https://efficientml.ai
두 번째는 그럼 적은 메모리를 잘 이용하기 위해 Neural Network에서 어떤 데이터를 신경써야 하는 가 이다. 크게 Flash 메모리에서 저장하고 읽기를 주로하는 Parameter나 Weight와 같이 Synapses와 연관된 데이터. 그리고 SRAM에 저장하고 자주 읽기 쓰기를 반복하는 Feature나 Activation으로 나눌 수 있을 것이다.
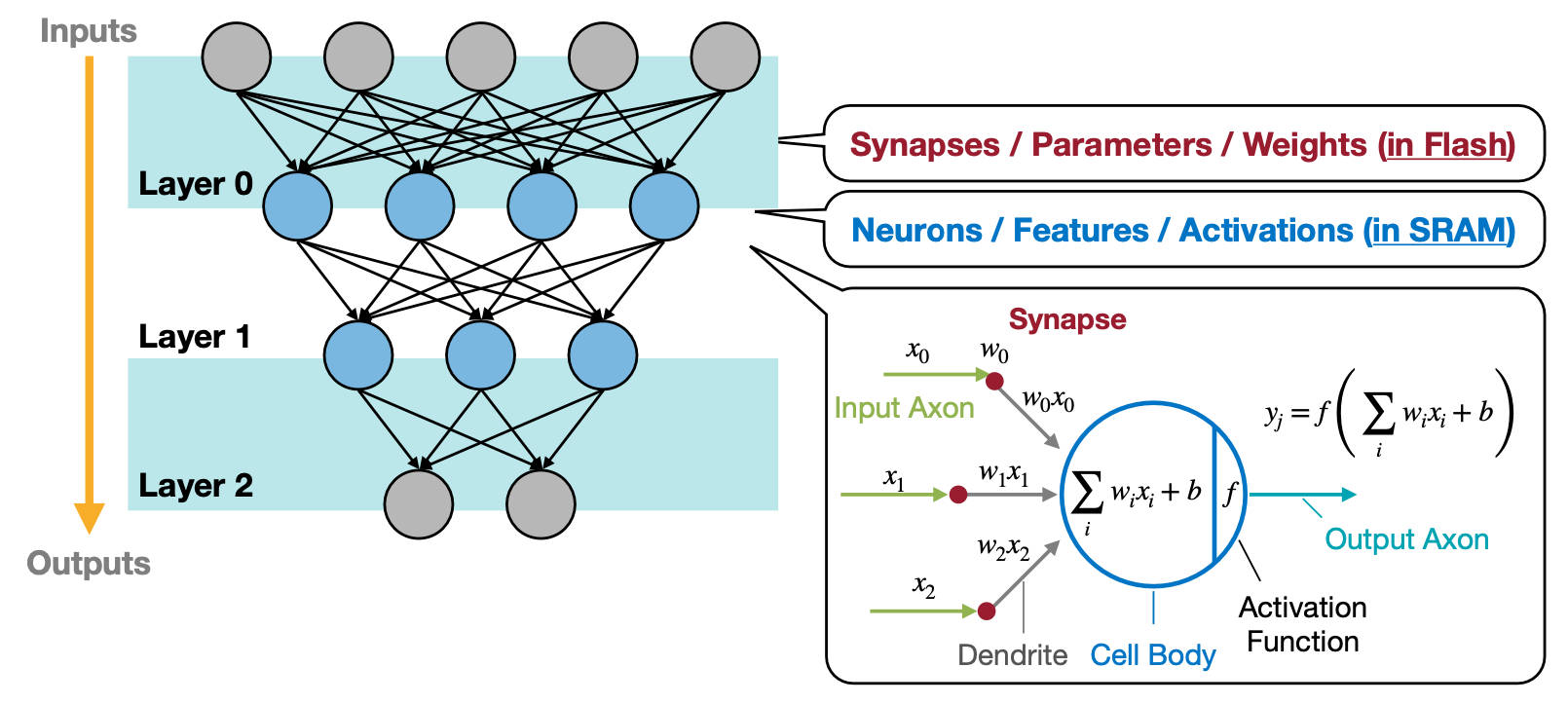
Reference. MIT-TinyML-lecture17-TinyEngine in https://efficientml.ai
마지막으로는 “Primary Data Layout”이라고 언급되는 데이터가 어떻게 배열되는가 이다. Caffe와 Tensorflow에서 차원수가 높아지면서 데이터의 배열에 따라 Cache를 얼마나 잘 사용할 수 있는가를 고려할 수 있다. 이 점은 Tensorflow를 이용한 예제가 이후에 나올 텐데, 여기서 FPS(Frame per second)에서 자세히 확인할 수 있다. 그리고 Tensorflow 예제를 고려하여 여러 다른 환경에서도 데이터가 어떻게 배열돼 있는지에 따라서 코드를 써 내려가야 할 것이다. 환경에 대한 한 가지 예시로, 이전에 무선이어폰에 DSP에서는 왼쪽, 오른쪽 데이터로 차례로 번갈아 오는 마이크 스트리밍 데이터가 있었다. 이는 이후 언급할 SIMD(Single Instruction, Multiple Data) 연산을 이용하면 데이터가 이미 배열돼서 오기 때문에 DSP 알고리즘 개발하는 업무에서는 연산속도를 2배가량 최적화를 고려할 수 있을 것이다.
3. Optimization Techniques in TinyEngine
3.1 Loop unrolling: Reduce loop
첫 번째 최적화 기법은 Loop unrolling이다. 아래처럼 for문을 도는 연산을 펼쳐 놓는 방법인데, ‘이게 정말 줄어들 수 있는거야?’하는 의구심이 먼저 든다. 강의에서 설명하기로는 크게 for 루프에서 3가지 overhead를 줄일 수 있다.
- Arithmetic operations for pointers(e.g. i, j, k): \(N^3 \rightarrow \frac{1}{4}N^3\)
- End of loop test (e.g. k < N): \(N^3 \rightarrow \frac{1}{4}N^3\)
- Branch prediction
이렇게 펼쳐놓음으로써 가독성이 안좋아질 수 있고 코드 길이는 4배만큼 unrolling을 하는 경우 4배나 늘어나긴 하겠지만, 뒤에 예제에서 확인하듯 실제로 여기에 언급된 최적화 기법들을 적용하면 단위 시간당 프레임 수가 점점 늘어나는 것을 확인할 수 있을 것이다.

Reference. MIT-TinyML-lecture17-TinyEngine in https://efficientml.ai
3.2 Loop reordering: Cache locality
두 번째 최적화 기법은 Loop reordering이다. “Loop에서 데이터를 읽는 순서만 바꿔서 data locality를 늘려 Cache를 잘 사용하자!”는 방법이다. 그림을 보면 행렬 A와 행렬 B의 데이터를 읽는 순서를 맞추기 위해 (i, j, k)에서 (i, k, j)로 바뀐 것을 볼 수 있다.

Reference. MIT-TinyML-lecture17-TinyEngine in https://efficientml.ai
3.3 Loop Tiling: Reduce cache miss
세 번째 최적화 기법은 Loop Tiling이다. 이 방법 또한 Loop Reordering과 동일하게 Cache miss를 줄이기 위한 방법인데, 행렬 A, B의 곱을 구할 때 특정 구역을 정해서 그 구역 안에서만 계산을 하고 다음 구역으로 넘어가는 방법이다. 이 방법을 쓰려면 Cache size를 고려해서 구역크기를 정해야지, 오히려 크기가 cache보다 크면 cache miss가 더 높아져 역효과를 낼 수도 있다.
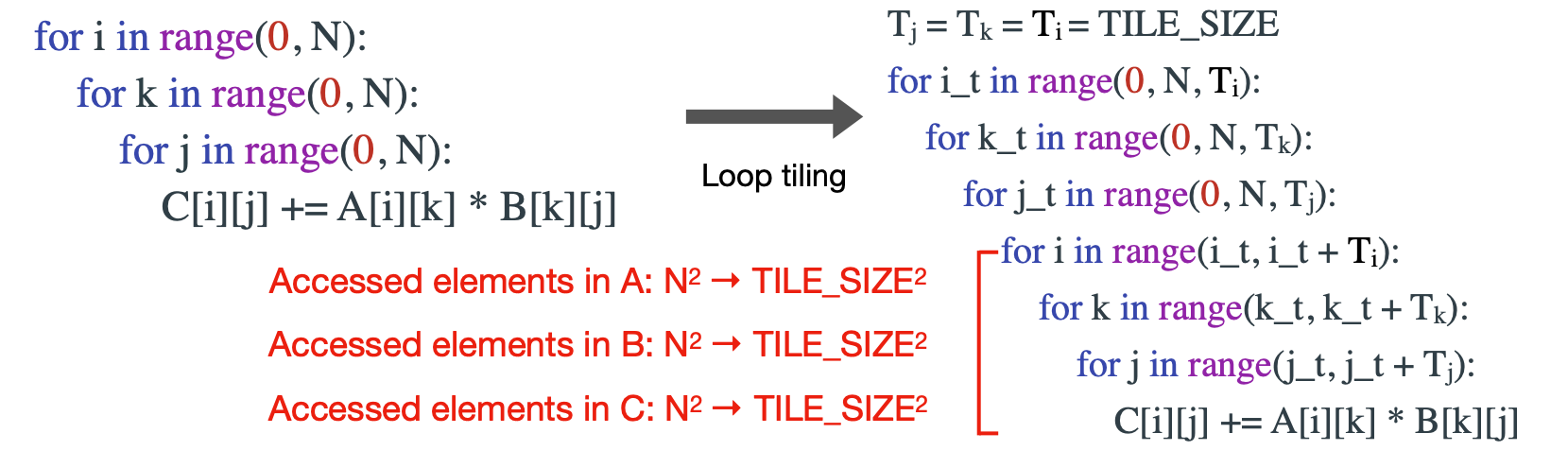
Reference. MIT-TinyML-lecture17-TinyEngine in https://efficientml.ai
아무래도 Cache의 크기가 제한적이기 때문에 이를 더 잘 활용하기 위해서 Multilvel tiling이라는 방법을 사용한다. 행렬 A를 작은 A’로, 더 작은 A’‘로 만든다는 이야기인데,

Reference. MIT-TinyML-lecture17-TinyEngine in https://efficientml.ai
이를 행렬 A, B에 적용하면 다음처럼 된다.
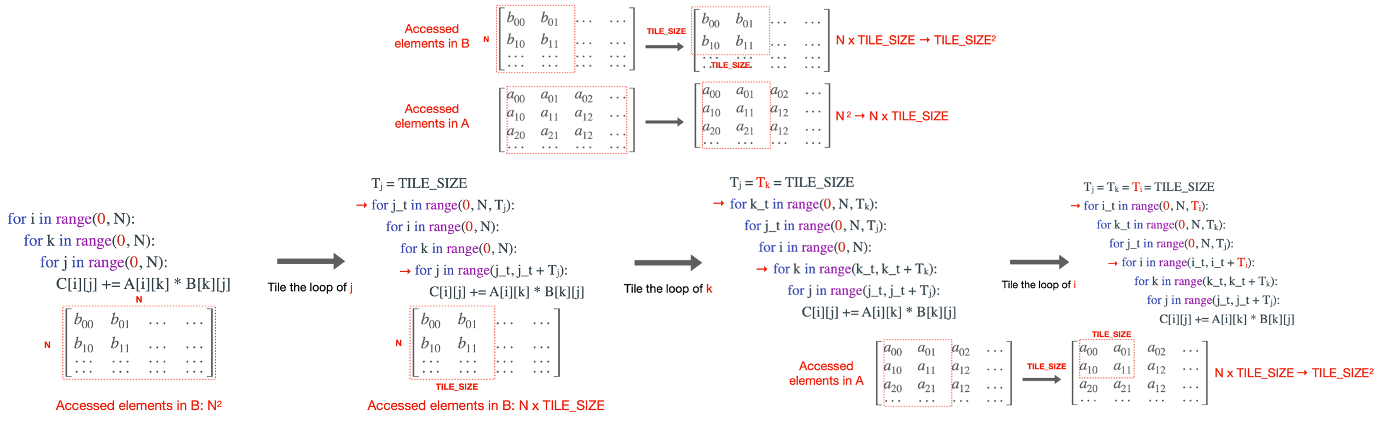
Reference. MIT-TinyML-lecture17-TinyEngine in https://efficientml.ai
3.4 SIMD (single instruction, multiple data) programming
네 번째 최적화 기법은 SIMD programming이다. 이 방법은 “하나의 operation으로 여러 데이터를 처리하자”는 컨셉인데 아래처럼 32bit 연산을 한번에 4개를 처리헐 수 있다. 언뜻 보면 이는 데이터를 연속으로 배열해야하지만 이를 통해 연산량을 1/4배 할 수 있게 보이지만 데이터를 특정 배열대로 있어야 가능하기에, 데이터의 layer를 고려해야하는 부분이 있다. 아래 그림을 보면 dot_vec4와 같이 다양한 타입(e.g. int8, float16 … )과 여러 연산 (e.g. 덧셈, 곱셈 …) 을 각 디바이스마다 가지고 있으니, 특정 기기만 사용하는 업무라면 최적화하는데 고려해볼 수도?
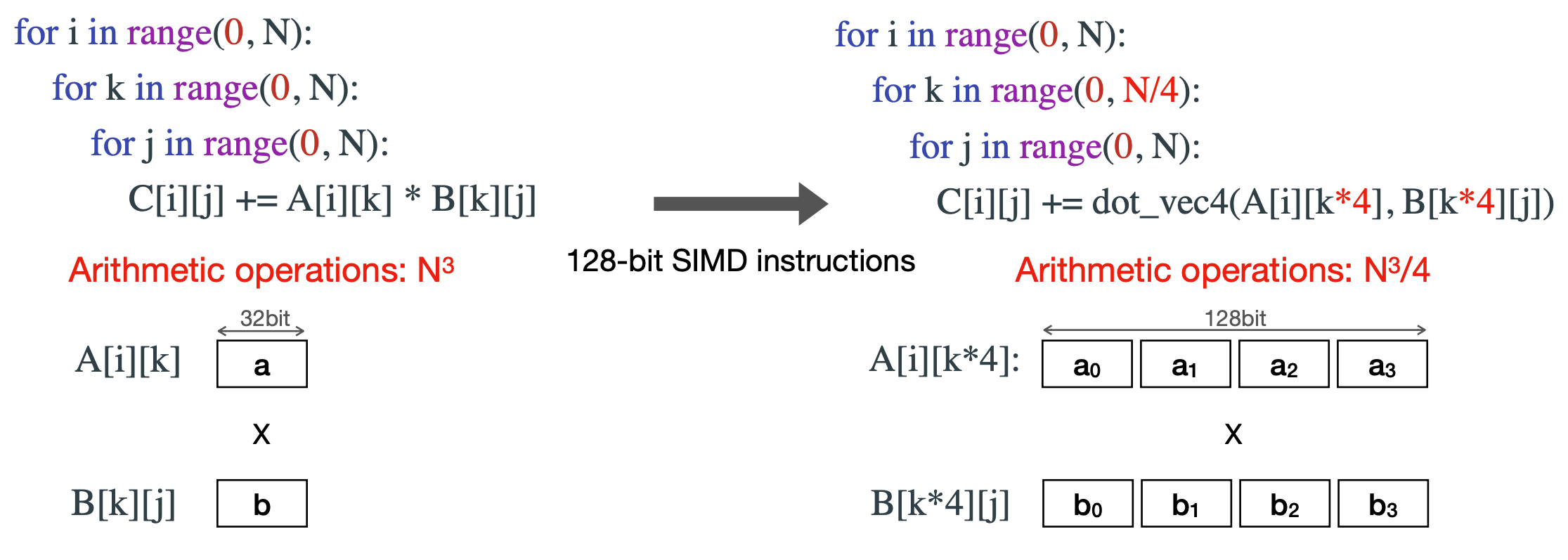
Reference. MIT-TinyML-lecture17-TinyEngine in https://efficientml.ai
4. Example for Loop Unrolling, Loop reordering and SIMD programming
TinyML에 관련한 강의에서는 STM32F746 Discovery보드를 이용해서 에제를 제공하고 있다. 물론 엄청 제한적인 환경은 아니지만 임베디드 환경이면서도 메모리와 M7 시리즈를 쓰고 있는 빵빵한 녀석이라 최적화 기법을 실험해보기 좋다.
다음 기법으로 넘어가기전에 앞에서 설명한 기법 중 Loop Unrolling와 Loop reordering의 예제를 짚고 넘어가 보자. 최적화 기법을 적용해 볼 함수는 uint8 convolution 1x1 함수이다. 우선 최적화 기법을 사용하고 표현해보면 아래와 같이 된다. 커널의 값과 input의 값을 차례로 불러와서 결과(sum)를 낸 후 bias를 더한 다음 Quantiazation을 다시 하는 것을 볼 수 있다.
int OffsetC(const uint16_t data1, const uint16_t data2, const uint16_t data3, int i0, int i1, int i2, int i3) {
return ((i0 * data1 + i1) * data2 + i2) * data3 + i3;
}
tinyengine_status convolve_1x1_s8_fpreq(const q7_t *input,
const uint16_t input_x, const uint16_t input_y, const uint16_t input_ch,
const q7_t *kernel, const int32_t *bias, const float *scales,
const int32_t out_offset, const int32_t input_offset,
const int32_t out_activation_min, const int32_t out_activation_max,
q7_t *output, const uint16_t output_x, const uint16_t output_y,
const uint16_t output_ch, q15_t *runtime_buf)
{
for (int out_y = 0; out_y < output_y; ++out_y) {
for (int out_x = 0; out_x < output_x; ++out_x) {
for (int out_channel = 0; out_channel < output_ch; ++out_channel) {
int32_t sum = 0;
for (int filter_y = 0; filter_y < DIM_KER_Y; ++filter_y) {
for (int filter_x = 0; filter_x < DIM_KER_X; ++filter_x) {
for (int in_channel = 0; in_channel < input_ch; ++in_channel) {
int32_t input_val = input[OffsetC(input_y, input_x, input_ch, 0, out_y, out_x, in_channel)];
int32_t filter_val = kernel[OffsetC(DIM_KER_Y, DIM_KER_X, input_ch, out_channel, filter_y, filter_x, in_channel)];
sum += filter_val * (input_val + input_offset);
}
}
}
if (bias) {
sum += bias[out_channel];
}
sum = (int32_t) ((float)sum * scales[out_channel]);
sum += out_offset;
sum = MAX(sum, out_activation_min);
sum = MIN(sum, out_activation_max);
output[OffsetC(output_y, output_x, output_ch, 0, out_y, out_x, out_channel)] = (int8_t)(sum);
}
}
}
}
4.1 Loop Unrolling
첫 번째로 Loop Unrolling을 적용해보자. 코드에서 LOOP_UNROLLING가 선언된 부분과 아닌 부분을 보면 단순히 펼쳐진 것을 볼 수 있다.
tinyengine_status convolve_1x1_s8_fpreq(const q7_t *input,
const uint16_t input_x, const uint16_t input_y, const uint16_t input_ch,
const q7_t *kernel, const int32_t *bias, const float *scales,
const int32_t out_offset, const int32_t input_offset,
const int32_t out_activation_min, const int32_t out_activation_max,
q7_t *output, const uint16_t output_x, const uint16_t output_y,
const uint16_t output_ch, q15_t *runtime_buf)
{
if (input_ch % 4 != 0 || input_ch % 2 != 0) {
return PARAM_NO_SUPPORT;
}
int32_t i_element;
const int32_t num_elements = output_x * output_y;
(void) input_x;
(void) input_y;
q7_t *input_start = input;
const q7_t *kernel_start = kernel;
q7_t *out = output;
#if (!LOOP_UNROLLING)
for (i_element = 0; i_element < num_elements; i_element++) {
kernel = kernel_start;
for (int out_channel = 0; out_channel < output_ch; ++out_channel) {
int32_t sum = 0;
input = input_start;
for (int in_channel = 0; in_channel < input_ch; ++in_channel) {
int32_t input_val = *input++;
int32_t filter_val = *kernel++;
sum += filter_val * (input_val + input_offset);
}
if (bias) {
sum += bias[out_channel];
}
sum = (int32_t) ((float)sum * scales[out_channel]);
sum += out_offset;
sum = MAX(sum, out_activation_min);
sum = MIN(sum, out_activation_max);
*out++ = (int8_t)(sum);
}
input_start += input_ch;
}
#else // if (LOOP_UNROLLING)
for (i_element = 0; i_element < num_elements / 2; i_element++) {
q7_t *kernel_0 = kernel_start;
q7_t *kernel_1 = kernel_start + input_ch;
q7_t *out_0 = output;
q7_t *out_1 = output + output_ch;
for (int out_channel = 0; out_channel < output_ch / 2; ++out_channel) {
int32_t sum_0 = 0;
int32_t sum_1 = 0;
int32_t sum_2 = 0;
int32_t sum_3 = 0;
q7_t *input_0 = input_start;
q7_t *input_1 = input_start + input_ch;
for (int in_channel = 0; in_channel < input_ch / 4; ++in_channel) {
int32_t input_val = *input_0;
int32_t filter_val = *kernel_0;
sum_0 += filter_val * (input_val + input_offset);
input_val = *input_1;
filter_val = *kernel_0++;
sum_1 += filter_val * (input_val + input_offset);
input_val = *input_0++;
filter_val = *kernel_1;
sum_2 += filter_val * (input_val + input_offset);
input_val = *input_1++;
filter_val = *kernel_1++;
sum_3 += filter_val * (input_val + input_offset);
input_val = *input_0;
filter_val = *kernel_0;
sum_0 += filter_val * (input_val + input_offset);
input_val = *input_1;
filter_val = *kernel_0++;
sum_1 += filter_val * (input_val + input_offset);
input_val = *input_0++;
filter_val = *kernel_1;
sum_2 += filter_val * (input_val + input_offset);
input_val = *input_1++;
filter_val = *kernel_1++;
sum_3 += filter_val * (input_val + input_offset);
input_val = *input_0;
filter_val = *kernel_0;
sum_0 += filter_val * (input_val + input_offset);
input_val = *input_1;
filter_val = *kernel_0++;
sum_1 += filter_val * (input_val + input_offset);
input_val = *input_0++;
filter_val = *kernel_1;
sum_2 += filter_val * (input_val + input_offset);
input_val = *input_1++;
filter_val = *kernel_1++;
sum_3 += filter_val * (input_val + input_offset);
input_val = *input_0;
filter_val = *kernel_0;
sum_0 += filter_val * (input_val + input_offset);
input_val = *input_1;
filter_val = *kernel_0++;
sum_1 += filter_val * (input_val + input_offset);
input_val = *input_0++;
filter_val = *kernel_1;
sum_2 += filter_val * (input_val + input_offset);
input_val = *input_1++;
filter_val = *kernel_1++;
sum_3 += filter_val * (input_val + input_offset);
}
if (bias) {
sum_0 += bias[out_channel * 2];
sum_1 += bias[out_channel * 2];
sum_2 += bias[out_channel * 2 + 1];
sum_3 += bias[out_channel * 2 + 1];
}
sum_0 = (int32_t) ((float)sum_0 * scales[out_channel * 2]);
sum_0 += out_offset;
sum_0 = MAX(sum_0, out_activation_min);
sum_0 = MIN(sum_0, out_activation_max);
*out_0++ = (int8_t)(sum_0);
sum_1 = (int32_t) ((float)sum_1 * scales[out_channel * 2]);
sum_1 += out_offset;
sum_1 = MAX(sum_1, out_activation_min);
sum_1 = MIN(sum_1, out_activation_max);
*out_1++ = (int8_t)(sum_1);
sum_2 = (int32_t) ((float)sum_2 * scales[out_channel * 2 + 1]);
sum_2 += out_offset;
sum_2 = MAX(sum_2, out_activation_min);
sum_2 = MIN(sum_2, out_activation_max);
*out_0++ = (int8_t)(sum_2);
sum_3 = (int32_t) ((float)sum_3 * scales[out_channel * 2 + 1]);
sum_3 += out_offset;
sum_3 = MAX(sum_3, out_activation_min);
sum_3 = MIN(sum_3, out_activation_max);
*out_1++ = (int8_t)(sum_3);
kernel_0 += input_ch;
kernel_1 += input_ch;
}
input_start += input_ch * 2;
output += output_ch * 2;
}
/* check if there is an odd column left-over for computation */
if (num_elements & 0x1) {
q7_t *kernel_0 = kernel_start;
q7_t *kernel_1 = kernel_start + input_ch;
q7_t *out_0 = output;
for (int out_channel = 0; out_channel < output_ch / 2; ++out_channel) {
int32_t sum_0 = 0;
int32_t sum_1 = 0;
q7_t *input_0 = input_start;
for (int in_channel = 0; in_channel < input_ch / 4; ++in_channel) {
int32_t input_val = *input_0;
int32_t filter_val = *kernel_0++;
sum_0 += filter_val * (input_val + input_offset);
input_val = *input_0++;
filter_val = *kernel_1++;
sum_1 += filter_val * (input_val + input_offset);
input_val = *input_0;
filter_val = *kernel_0++;
sum_0 += filter_val * (input_val + input_offset);
input_val = *input_0++;
filter_val = *kernel_1++;
sum_1 += filter_val * (input_val + input_offset);
input_val = *input_0;
filter_val = *kernel_0++;
sum_0 += filter_val * (input_val + input_offset);
input_val = *input_0++;
filter_val = *kernel_1++;
sum_1 += filter_val * (input_val + input_offset);
input_val = *input_0;
filter_val = *kernel_0++;
sum_0 += filter_val * (input_val + input_offset);
input_val = *input_0++;
filter_val = *kernel_1++;
sum_1 += filter_val * (input_val + input_offset);
}
if (bias) {
sum_0 += bias[out_channel * 2];
sum_1 += bias[out_channel * 2 + 1];
}
sum_0 = (int32_t) ((float)sum_0 * scales[out_channel * 2]);
sum_0 += out_offset;
sum_0 = MAX(sum_0, out_activation_min);
sum_0 = MIN(sum_0, out_activation_max);
*out_0++ = (int8_t)(sum_0);
sum_1 = (int32_t) ((float)sum_1 * scales[out_channel * 2 + 1]);
sum_1 += out_offset;
sum_1 = MAX(sum_1, out_activation_min);
sum_1 = MIN(sum_1, out_activation_max);
*out_0++ = (int8_t)(sum_1);
kernel_0 += input_ch;
kernel_1 += input_ch;
}
}
#endif // end of (!LOOP_UNROLLING)
}
4.2 Loop reordering
두 번째는 Loop reordering 이다. 전체적인 코드는 강의 예제 코드를 보면 알 수 있지만, 중요한 핵심은 포인터를 이용해서 순차적으로 데이터를 읽어서 연산한다는 컨셉으로 이해했다. 뒤에 SIMD programming까지 이어서 보면 이해가 더 쉬울 것이다.
// ...
#if LOOP_REORDERING
for (i_element = 0; i_element < num_elements / 2; i_element++) {
/* Fill buffer for partial im2col - two columns at a time */
q7_t *src = &input[i_element * input_ch * 2];
#else // if (!LOOP_REORDERING)
for (int batch = 0; batch < batches; ++batch) {
for (int out_y = 0; out_y < output_y; ++out_y) {
//const int in_y_origin = (out_y * stride_height) - pad_height;
for (int out_x = 0; out_x < output_x / 2; ++out_x) {
//const int in_x_origin = (out_x * stride_width) - pad_width;
q7_t *src = &input[(out_y * output_x + out_x) * input_ch * 2];
#endif // end of LOOP_REORDERING
// ...
4.3 SIMD programming
세 번째는 SIMD programming이다. 이후 4.4 All together에서 나오겠지만, convolution 연산을 위한 SIMD는 아래 4가지 단계를 거친다.
-
필요에 따라, 미리 SIMD 연산을 위한 버퍼를 준비한다. __PKHBT는 ARM_MATH_DSP에서 제공하는 Shift연산으로 32bit에 16bit를 두 개 넣는 연산을 의미하는데, 여기선 input offset을 연산하기 위해 미리 계산한 것이다.
#include "arm_math.h" // ... q31_t offset_q15x2 = __PKHBT(inoff16, inoff16, 16);// arm_math.h dsp/none.h #ifndef ARM_MATH_DSP /** * @brief definition to pack two 16 bit values. */ #define __PKHBT(ARG1, ARG2, ARG3) ( (((int32_t)(ARG1) << 0) & (int32_t)0x0000FFFF) | \ (((int32_t)(ARG2) << ARG3) & (int32_t)0xFFFF0000) ) #endif -
입력 데이터를 SIMD연산을 위해 아래와 같이 재 배열한다.

#define q7_q15_offset_reordered_ele(src, dst) \ /* convert from q7 to q15 and then store the results in the destination buffer */ \ in_q7x4 = arm_nn_read_q7x4_ia((const q7_t **)&src); \ \ /* Extract and sign extend each of the four q7 values to q15 */ \ out_q15x2_1 = __SXTB16(__ROR(in_q7x4, 8)); \ out_q15x2_2 = __SXTB16(in_q7x4); \ \ out_q15x2_1 = __SADD16(out_q15x2_1, offset_q15x2); \ out_q15x2_2 = __SADD16(out_q15x2_2, offset_q15x2); \ \ write_q15x2_ia(&dst, out_q15x2_2); \ write_q15x2_ia(&dst, out_q15x2_1); - 입력 데이터를 차례로 읽고, 커널(ip_a0, ip_a1)도 입력데이터와 같이 데이터를 재 배열한다. 이때 커널에서 채널을 2개씩 읽어서 사용한다. 여기서 Unrolling을 하면 loop를 펼쳐놓으면 된다.
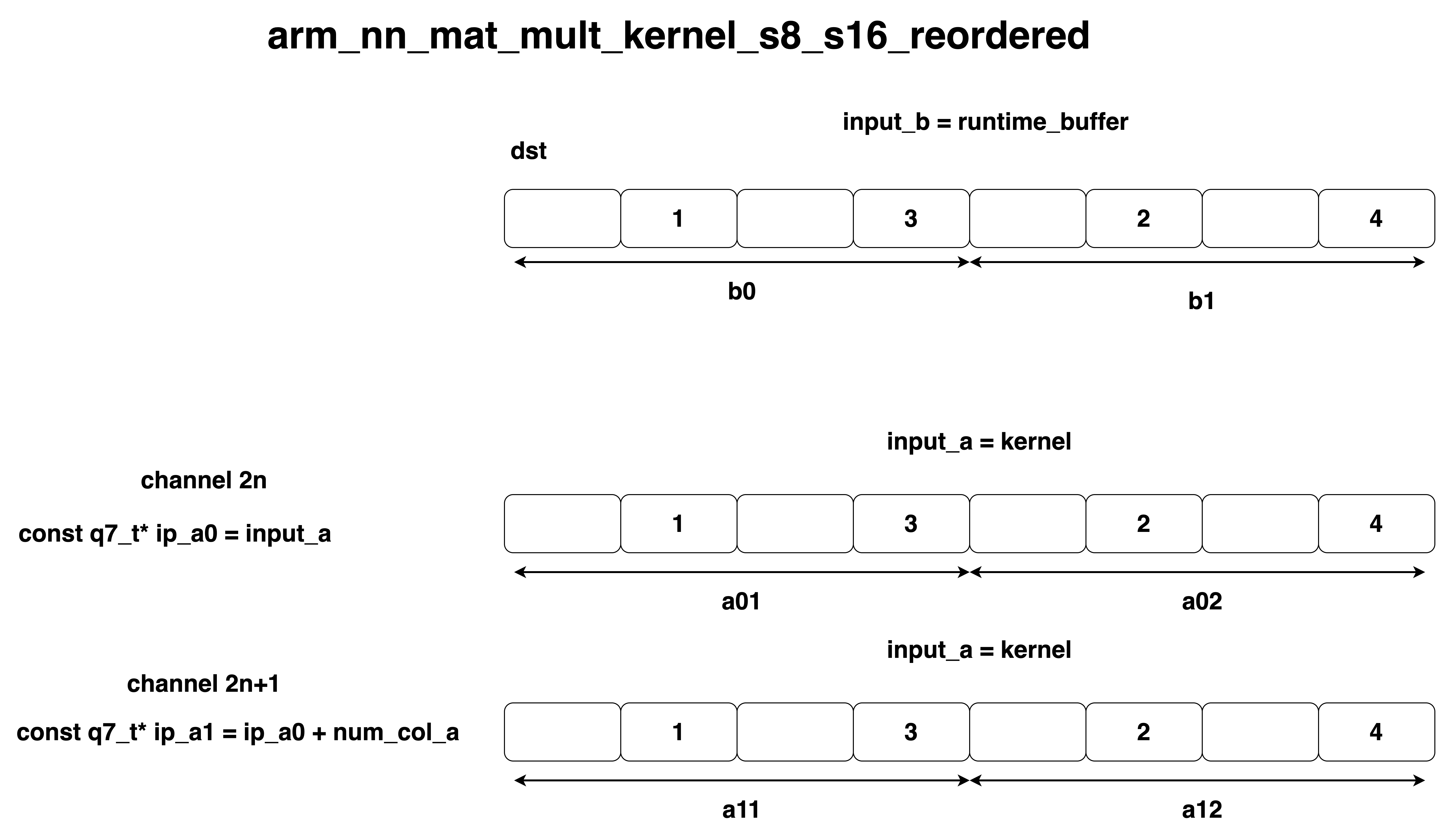
Reference. MIT-TinyML-lecture17-TinyEngine in https://efficientml.ai
q31_t b0 = arm_nn_read_q15x2_ia(&ip_b0); q31_t b1 = arm_nn_read_q15x2_ia(&ip_b1); ip_a0 = read_and_pad_reordered(ip_a0, &a01, &a02); ip_a1 = read_and_pad_reordered(ip_a1, &a11, &a12); -
SIMD Compute!
ch_0_out_0 = __SMLAD(a01, b0, ch_0_out_0); ch_0_out_1 = __SMLAD(a01, b1, ch_0_out_1); ch_1_out_0 = __SMLAD(a11, b0, ch_1_out_0); ch_1_out_1 = __SMLAD(a11, b1, ch_1_out_1);
4.4.All together
앞서 말한 Loop unrolling, Loop reordering, SIMD programming을 이용해서 최적화한 uint8 convolution 1x1 함수이다.
q7_t *arm_nn_mat_mult_kernel_s8_s16_reordered(const q7_t *input_a,
const q15_t *input_b,
const uint16_t output_ch,
const int32_t *out_shift,
const int32_t *out_mult,
const int32_t out_offset,
const int16_t activation_min,
const int16_t activation_max,
const uint16_t num_col_a,
const int32_t *const output_bias,
q7_t *out_0)
{
#if defined(ARM_MATH_DSP)
/* set up the second output pointers */
q7_t *out_1 = out_0 + output_ch;
const int32_t *bias = output_bias;
uint16_t row_count = output_ch / 2;
const q7_t *ip_a0 = input_a;
/* this loop over rows in A */
while (row_count)
{
/* setup pointers for B */
const q15_t *ip_b0 = input_b;
const q15_t *ip_b1 = ip_b0 + num_col_a;
/* align the second pointer for A */
const q7_t *ip_a1 = ip_a0 + num_col_a;
/* Init accumulator with bias for channel N and N + 1 */
q31_t ch_0_out_0 = *bias;
q31_t ch_0_out_1 = *bias++;
q31_t ch_1_out_0 = *bias;
q31_t ch_1_out_1 = *bias++;
uint16_t col_count = num_col_a / 4;
/* accumulate over the vector */
while (col_count)
{
q31_t a01, a02, a11, a12;
q31_t b0 = arm_nn_read_q15x2_ia(&ip_b0);
q31_t b1 = arm_nn_read_q15x2_ia(&ip_b1);
ip_a0 = read_and_pad_reordered(ip_a0, &a01, &a02);
ip_a1 = read_and_pad_reordered(ip_a1, &a11, &a12);
ch_0_out_0 = __SMLAD(a01, b0, ch_0_out_0);
ch_0_out_1 = __SMLAD(a01, b1, ch_0_out_1);
ch_1_out_0 = __SMLAD(a11, b0, ch_1_out_0);
ch_1_out_1 = __SMLAD(a11, b1, ch_1_out_1);
b0 = arm_nn_read_q15x2_ia(&ip_b0);
b1 = arm_nn_read_q15x2_ia(&ip_b1);
ch_0_out_0 = __SMLAD(a02, b0, ch_0_out_0);
ch_0_out_1 = __SMLAD(a02, b1, ch_0_out_1);
ch_1_out_0 = __SMLAD(a12, b0, ch_1_out_0);
ch_1_out_1 = __SMLAD(a12, b1, ch_1_out_1);
col_count--;
} /* while over col_count */
ch_0_out_0 = arm_nn_requantize(ch_0_out_0, *out_mult, *out_shift);
ch_0_out_0 += out_offset;
ch_0_out_0 = MAX(ch_0_out_0, activation_min);
ch_0_out_0 = MIN(ch_0_out_0, activation_max);
*out_0++ = (q7_t)ch_0_out_0;
ch_0_out_1 = arm_nn_requantize(ch_0_out_1, *out_mult, *out_shift);
ch_0_out_1 += out_offset;
ch_0_out_1 = MAX(ch_0_out_1, activation_min);
ch_0_out_1 = MIN(ch_0_out_1, activation_max);
*out_1++ = (q7_t)ch_0_out_1;
out_mult++;
out_shift++;
ch_1_out_0 = arm_nn_requantize(ch_1_out_0, *out_mult, *out_shift);
ch_1_out_0 += out_offset;
ch_1_out_0 = MAX(ch_1_out_0, activation_min);
ch_1_out_0 = MIN(ch_1_out_0, activation_max);
*out_0++ = (q7_t)ch_1_out_0;
ch_1_out_1 = arm_nn_requantize(ch_1_out_1, *out_mult, *out_shift);
ch_1_out_1 += out_offset;
ch_1_out_1 = MAX(ch_1_out_1, activation_min);
ch_1_out_1 = MIN(ch_1_out_1, activation_max);
*out_1++ = (q7_t)ch_1_out_1;
out_mult++;
out_shift++;
/* skip row */
ip_a0 += num_col_a;
row_count--;
}
if (output_ch & 1)
{
/* setup pointers for B */
const q15_t *ip_b0 = input_b;
const q15_t *ip_b1 = ip_b0 + num_col_a;
/* Init accumulator with bias for channel N + 1 */
q31_t ch_0_out_0 = *bias;
q31_t ch_0_out_1 = ch_0_out_0;
int32_t col_count = num_col_a / 4;
while (col_count)
{
q31_t a01, a02;
q31_t b0 = arm_nn_read_q15x2_ia(&ip_b0);
q31_t b1 = arm_nn_read_q15x2_ia(&ip_b1);
ip_a0 = read_and_pad_reordered(ip_a0, &a01, &a02);
ch_0_out_0 = __SMLAD(a01, b0, ch_0_out_0);
ch_0_out_1 = __SMLAD(a01, b1, ch_0_out_1);
b0 = arm_nn_read_q15x2_ia(&ip_b0);
b1 = arm_nn_read_q15x2_ia(&ip_b1);
ch_0_out_0 = __SMLAD(a02, b0, ch_0_out_0);
ch_0_out_1 = __SMLAD(a02, b1, ch_0_out_1);
col_count--;
} /* while over col_count */
ch_0_out_0 = arm_nn_requantize(ch_0_out_0, *out_mult, *out_shift);
ch_0_out_0 += out_offset;
ch_0_out_0 = MAX(ch_0_out_0, activation_min);
ch_0_out_0 = MIN(ch_0_out_0, activation_max);
*out_0++ = (q7_t)ch_0_out_0;
ch_0_out_1 = arm_nn_requantize(ch_0_out_1, *out_mult, *out_shift);
ch_0_out_1 += out_offset;
ch_0_out_1 = MAX(ch_0_out_1, activation_min);
ch_0_out_1 = MIN(ch_0_out_1, activation_max);
*out_1++ = (q7_t)ch_0_out_1;
}
out_0 += output_ch;
/* return the new output pointer with offset */
return out_0;
#endif
}
#define q7_q15_offset_reordered_ele(src, dst) \
/* convert from q7 to q15 and then store the results in the destination buffer */ \
in_q7x4 = arm_nn_read_q7x4_ia((const q7_t **)&src); \
\
/* Extract and sign extend each of the four q7 values to q15 */ \
out_q15x2_1 = __SXTB16(__ROR(in_q7x4, 8)); \
out_q15x2_2 = __SXTB16(in_q7x4); \
\
out_q15x2_1 = __SADD16(out_q15x2_1, offset_q15x2); \
out_q15x2_2 = __SADD16(out_q15x2_2, offset_q15x2); \
\
write_q15x2_ia(&dst, out_q15x2_2); \
write_q15x2_ia(&dst, out_q15x2_1);
tinyengine_status convolve_1x1_s8(const q7_t *input, const uint16_t input_x,
const uint16_t input_y, const uint16_t input_ch, const q7_t *kernel,
const int32_t *bias, const int32_t *output_shift,
const int32_t *output_mult, const int32_t out_offset,
const int32_t input_offset, const int32_t out_activation_min,
const int32_t out_activation_max, q7_t *output, const uint16_t output_x,
const uint16_t output_y, const uint16_t output_ch, q15_t *runtime_buf) {
#if SIMD
int32_t i_element;
(void) input_x;
(void) input_y;
/* Partial(two columns) im2col buffer */
q15_t *two_column_buffer = runtime_buf;
q7_t *out = output;
const int32_t num_elements = output_x * output_y;
const int channel_div4 = (input_ch >> 2);
const int16_t inoff16 = input_offset;
q31_t offset_q15x2 = __PKHBT(inoff16, inoff16, 16);
const int batches = 1;
#if LOOP_REORDERING
for (i_element = 0; i_element < num_elements / 2; i_element++) {
/* Fill buffer for partial im2col - two columns at a time */
q7_t *src = &input[i_element * input_ch * 2];
q15_t *dst = two_column_buffer;
//use variables
q31_t in_q7x4;
q31_t in_q15x2_1;
q31_t in_q15x2_2;
q31_t out_q15x2_1;
q31_t out_q15x2_2;
int cnt = channel_div4; //two columns
while (cnt > 0) {
q7_q15_offset_reordered_ele(src, dst)
q7_q15_offset_reordered_ele(src, dst)
cnt--;
}
#if LOOP_UNROLLING
out = mat_mult_kernel_s8_s16_reordered_ch8(kernel,
two_column_buffer, output_ch, output_shift, output_mult,
(q7_t) out_offset, out_activation_min,
out_activation_max, input_ch * DIM_KER_Y * DIM_KER_X,
bias, out);
#else // if (!LOOP_UNROLLING)
out = arm_nn_mat_mult_kernel_s8_s16_reordered(kernel,
two_column_buffer, output_ch, output_shift, output_mult,
(q7_t) out_offset, out_activation_min,
out_activation_max, input_ch * DIM_KER_Y * DIM_KER_X,
bias, out);
#endif // end of LOOP_UNROLLING
#if LOOP_REORDERING
}
/* check if there is an odd column left-over for computation */
if (num_elements & 0x1) {
int32_t i_ch_out;
const q7_t *ker_a = kernel;
q7_t *src = &input[(num_elements - 1) * input_ch];
q15_t *dst = two_column_buffer;
//use variables
q31_t in_q7x4;
q31_t in_q15x2_1;
q31_t in_q15x2_2;
q31_t out_q15x2_1;
q31_t out_q15x2_2;
int cnt = channel_div4; //two * numof2col columns
while (cnt > 0) {
q7_q15_offset_reordered_ele(src, dst)
cnt--;
}
for (i_ch_out = 0; i_ch_out < output_ch; i_ch_out++) {
q31_t sum = bias[i_ch_out];
/* Point to the beginning of the im2col buffer where the input is available as a rearranged column */
const q15_t *ip_as_col = runtime_buf;
uint16_t col_count = (input_ch * DIM_KER_X * DIM_KER_Y) >> 2;
while (col_count) {
q31_t ker_a1, ker_a2;
q31_t in_b1, in_b2;
ker_a = read_and_pad_reordered(ker_a, &ker_a1, &ker_a2);
in_b1 = arm_nn_read_q15x2_ia(&ip_as_col);
sum = __SMLAD(ker_a1, in_b1, sum);
in_b2 = arm_nn_read_q15x2_ia(&ip_as_col);
sum = __SMLAD(ker_a2, in_b2, sum);
col_count--;
}
sum = arm_nn_requantize(sum, output_mult[i_ch_out],
output_shift[i_ch_out]);
sum += out_offset;
sum = MAX(sum, out_activation_min);
sum = MIN(sum, out_activation_max);
*out++ = (q7_t) sum;
}
}
#endif // LOOP_REORDERING
#endif // SIMD
}
Loop unrolling의 경우 코드 길이가 길어 적용 안된 것을 보고 이해한 후에 코드를 보면 좋다. 그럼 아래처럼 작성하면 얼마나 빨라질까? 결과부터 말하자면 아래 표처럼 FPS(Frame per second)가 기법 하나하나씩 더해갈 수록 빨리지는데, 실제로 보면 확실이 끊김이 덜하는 것을 체감할 수 있다. 나머지 내용인 Image to Column(Im2col) convolution, In-place depth-wise convolution, NHWC for point-wise convolution, and NCHW for depth-wise convolution, Winograd convolution은 다음 포스팅에서 계속!
| Techniques | FPS(Frame Per second) |
|---|---|
| Without techniques | 0.447 FPS |
| + Loop reorder | 1.386 FPS |
| + Im2col | 3.067 FPS |
| + HWC to CHW | 3.236 FPS |
| + Loop Unrolling | 5.347 FPS |
| + SIMD | 6.250 FPS |
| + Inplace depthwise convolution | 6.289 ~ 6.329 FPS |
To be continued… (1/2)