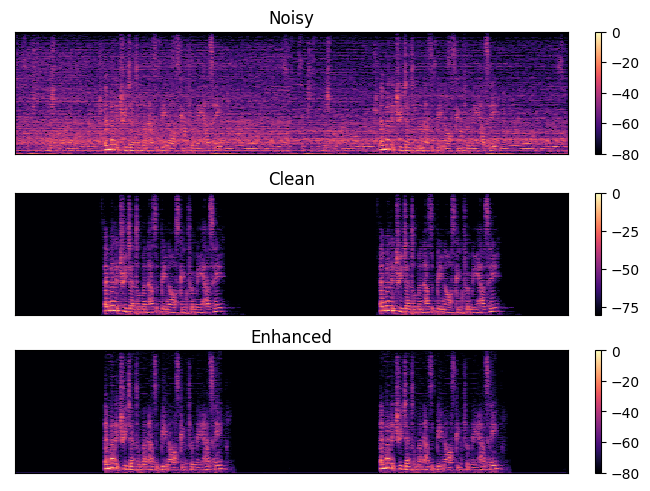
A result of Speech Enhancement
While developing speech enhancement for embedded devices targeting STM32F746, the chance to join 2023 ICASSP Clarity Challenge for Speech enhancement in hearing aid was coming.
In this challenge, it focus on amplificed speech quality using HASPI and HASQI metric, which can assess after processing amplification and compression for hearing-aid application. I focus on the problem of Speech Enhancement, Noise Reduction and Source Separation since the dataset in the challenge included several speakers (2 spks and 2 noise sources). It used Conv-Tasnet using Permutation Invariant Training(PIT). The repositories include two separate parts, one is the deep learning model, and the other is the hearing aid process/evaluation provided in the Clarity challenge. Those details includes belows applications. The results can show Top 5 rank, and I will continue to improve the model and the guide to implement the model to the tiny device for next project.
Applications
- Dataset/Dataloader for clean and noisy sound
- Training/Evaluating Model
- Amplification/Compression for Evaluation
- Amplification/Compression using Pytorch
Code for Model
Reference
[1] Kates, J.M. and Arehart, K.H., 2021. The hearing-aid speech perception index (HASPI) version 2. Speech Communication, 131, pp.35-46.
[2] Kates, J.M. and Arehart, K.H., 2014. “The hearing-aid speech quality index (HASQI) version 2”. Journal of the Audio Engineering Society. 62 (3): 99–117.
[3] Luo, Yi, and Nima Mesgarani. “Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation.” IEEE/ACM transactions on audio, speech, and language processing 27.8 (2019): 1256-1266.
[4] Kolbæk, Morten, et al. “Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks.” IEEE/ACM Transactions on Audio, Speech, and Language Processing 25.10 (2017): 1901-1913.