All contents is arranged from CS224N contents. Please see the details to the CS224N!
Intro
Why do we need sentence structure?
- Humans communicate complex ideas by composing words together into bigger units to convey complex meanings
- Listeners need to work out what modifies [attaches to] what
- A model needs to understand sentence structure in order to be able to interpret language correctly
But, there is ambiguity for several reasons as below,
-
PP(Prepositional) Attachment ambiguities multiply
-
Example 1. Scientists count whales from space
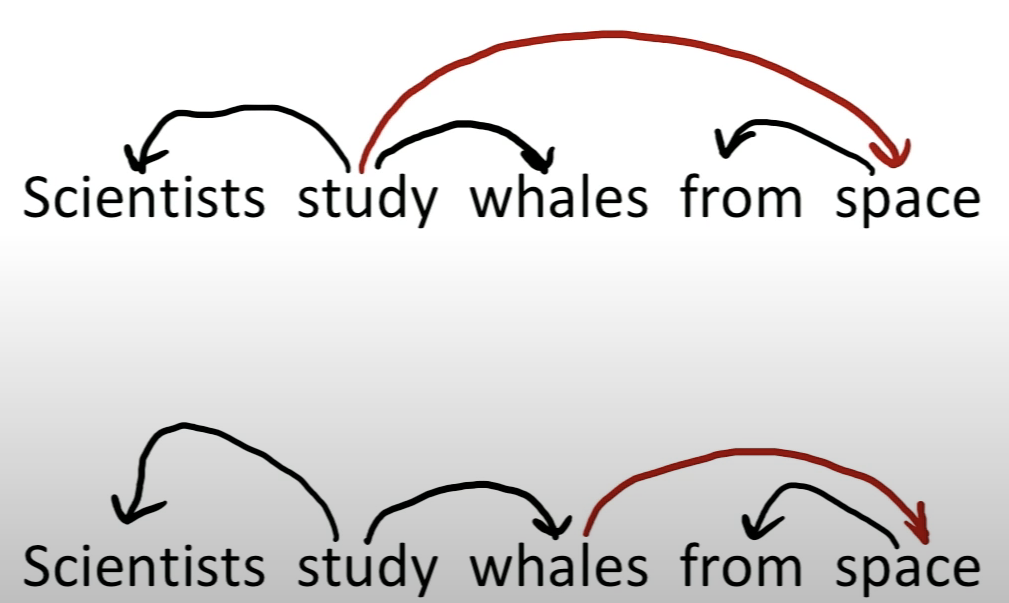
Reference. cs224n-2019-notes04-dependency-parsing
-
Example 2. The board approved its acquisition by Royal Trustco Ltd. of Toronto for $27 a share at its monthly meeting.
-
-
Coordination scope ambiguity
- Example. Doctor: No heart, cognitive issues
-
Adj, Adv Modifier Ambiguity
- Example. Students get first hand job experience.
-
Verb Phrase(VP) Attachment ambiguity
- Example. Mutilated body washes up on Rio beach to be used for Olympics beach volleyball
In this case, Dependency paths help extract semantic interpretation.
-
Practical example: extracting protein-protein interaction
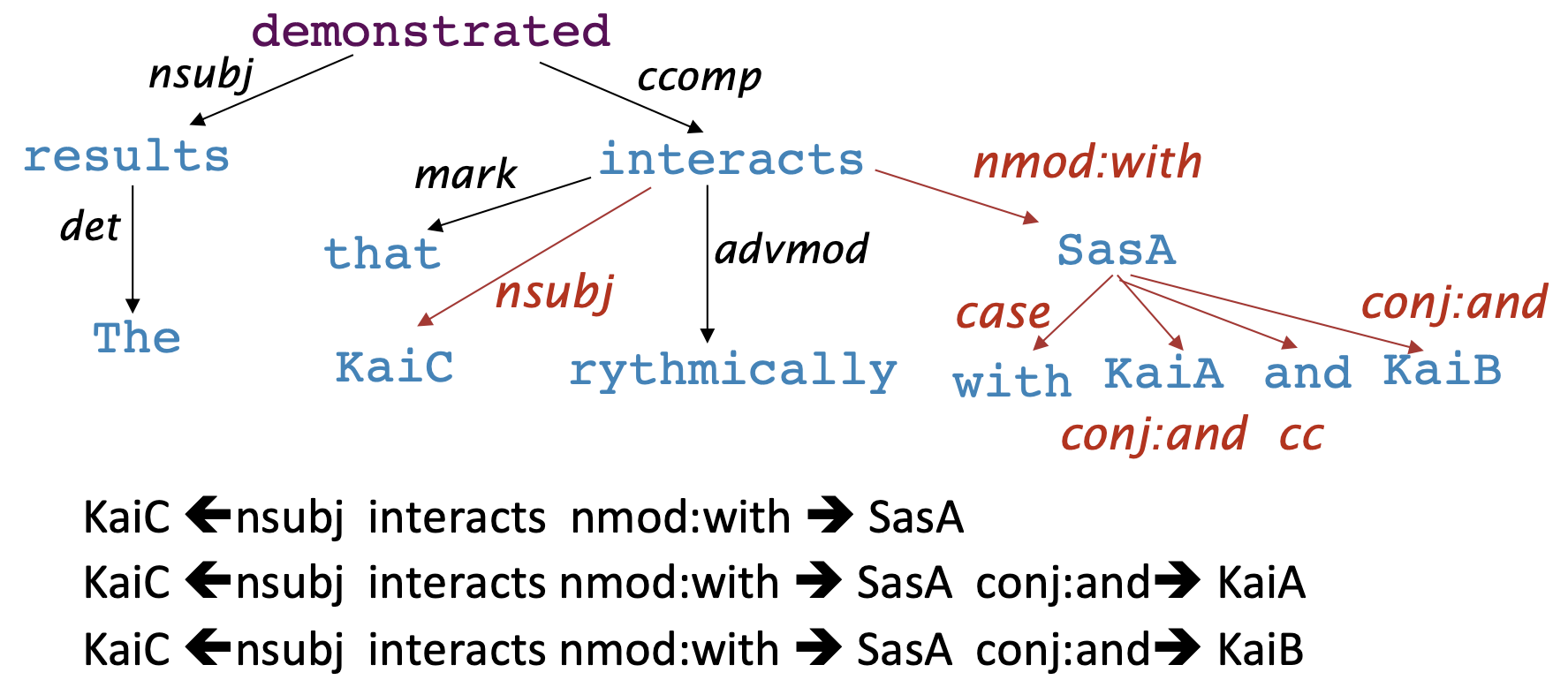
Reference. cs224n-2019-notes04-dependency-parsing
What is the Dependency?
Dependency syntax postulates that syntactic structure consists of relations between lexical items, normally binary asymmetric relations (“arrows”) called dependencies. These binary asymmetric relations between the words are called dependencies and are depicted as arrows going from the head (or governor, superior, regent) to the dependent (or modifier, inferior, subordinate). Usually, dependencies form a tree (a connected, acyclic, single-root graph).
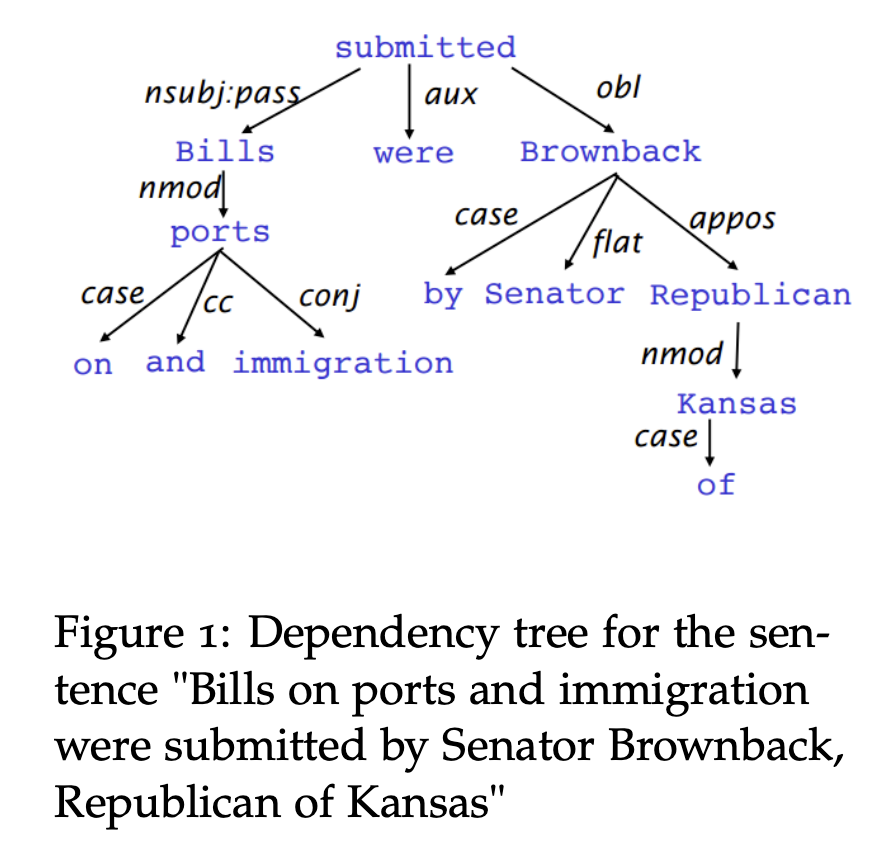
Reference. cs224n-2019-notes04-dependency-parsing
$\checkmark$ Dependency Grammar, Parsing History
-
The idea of dependency structure goes back a long way
- To Pāṇini’s grammar (c. 5th century BCE)
- Basic approach of 1st millennium Arabic grammarians
-
Constituency/context-free grammar is a new-fangled invention
- 20th century invention (R.S. Wells, 1947; then Chomsky 1953, etc.)
-
Modern dependency work is often sourced to Lucien Tesnière (1959)
- Was dominant approach in “East” in 20th Century (Russia, China, …)
- Good for free-er word order, inflected languages like Russian(or Latin!)
-
Used in some of the earliest parsers in NLP, even in the US:
- David Hays, one of the founders of U.S. computational linguistics, built early (first?) dependency parser (Hays 1962) and published on dependency grammar in Language
Then, How can we represent Dependency in the first time? Sometimes a fake ROOT node is added as the head to the whole tree so that every word is a dependent of exactly one node like below Figure.

Reference. cs224n-2019-notes04-dependency-parsing
$\checkmark$ What One of treebanks, “Annotated data” gives to us ?
Referred to Brown corpus (1967; PoS tagged 1979); Lancaster-IBM Treebank (starting late 1980s); Marcus et al. 1993, The Penn Treebank, Computational Linguistics;Universal Dependencies; (http://universaldependencies.org/)
Starting off, building a treebank seems a lot slower and less useful than writing a grammar (by hand). But a treebank gives us many things as below,
-
Reusability of the labor
- Many parsers, part-of-speech taggers,etc. can be built on it
- Valuable resource for linguistics
-
Broad coverage, not just a few intuitions
- Frequencies and distributional information
- A way to evaluate NLP systems
$\checkmark$ Dependency conditioning preferences
-
What are the sources of information for dependency parsing?
- Bilexical affinities, similarity between words: The dependency [discussion → issues] is plausible
- Dependency distance, density: Most dependencies are between nearby words
- Intervening material, dependency: Dependencies rarely span intervening verbs or punctuation
- Valency of heads, necessarity for sentence: How many dependents on which side are usual for a head?
-
Manual: Stanford-dependencies-manual.pdf
$\checkmark$ Dependency Parsing
- A sentence is parsed by choosing for each word what other word (including ROOT) it is a dependent of
- Usually some constraints:
- Only one word is a dependent of ROOT
- Don’t want cycles A→B, B→A
- This makes the dependencies tree
-
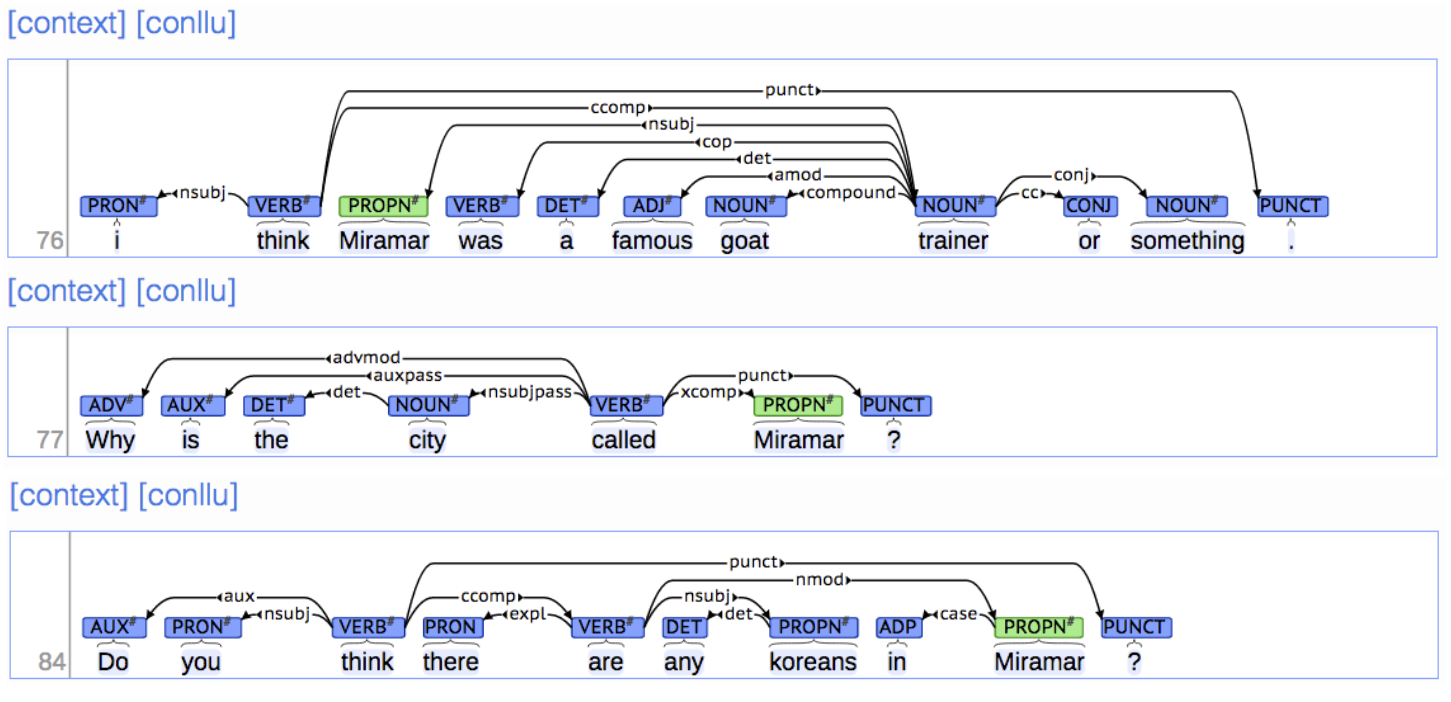
Final issue is whether arrows can cross (be non-projective) or not
As below sentense, long normination can refer the end of the sentence. If the location of constitutions for sentense, still “bootstrapping” modifys “talk”. This generates cross-line by changing those location. This is called as non-projective dependency tree. It means that when head connects a arrow to dependent, it should cross arrows for other head and dependent.

Reference. cs224n-2019-notes04-dependency-parsing
Reference: https://en.wikipedia.org/wiki/Dependency_grammar#Linear_order_and_discontinuities
- What is the Projectivity?
-
Definition of a projective parse
There are no crossing dependency arcs when the words are laid out in their linear order, with all arcs above the words
-
Dependencies corresponding to a CFG(Context-free Grammer) tree must be projective
I.e., by forming dependencies by taking 1 child of each category as head
-
Most syntactic structure is projective like this, but dependency theory normally does allow non-projective structures(Red line) to account for displaced constituents
You can’t easily get the semantics of certain constructions right without these non-projective dependencies

Reference. cs224n-2019-notes04-dependency-parsing
-
Methods of Dependency Parsing
-
Dynamic programming
Eisner (1996) gives a clever algorithm with complexity O(n3), by producing parse items with heads at the ends rather than in the middle
-
Graph algorithms
You create a Minimum Spanning Tree for a sentence. McDonald et al.’s (2005) MSTParser scores dependencies independently using an ML classifier (he uses MIRA, for online learning, but it can be something else)
Neural graph-based parser; Dozat and Manning (2017) et seq. – very successful!
-
Constraint Satisfaction
Edges are eliminated that don’t satisfy hard constraints. Karlsson (1990), etc. “Transition-based parsing” or “deterministic dependency parsing”
-
Greedy choice of attachments guided by good machine learning classifiers
E.g., MaltParser (Nivre et al. 2008). Has proven highly effective.
Dependency parsing is the task of analyzing the syntactic dependency structure of a given input sentence S. The output of a dependency parser is a dependency tree where the words of the input sentence are connected by typed dependency relations. Formally, the de- pendency parsing problem asks to create a mapping from the input sentence with words S = $w_0w_1…w_n$ (where $w_0$ is the ROOT) to its dependency tree graph G. Many different variations of dependency-based methods have been developed in recent years, including neural network-based methods, which it will describe later. To be precise, there are two sub problems in dependency parsing (adapted from Kuebler et al., chapter 1.2):
- Learning: Given a training set D of sentences annotated with dependency graphs, induce a parsing model M that can be used to parse new sentences.
- Parsing: Given a parsing model M and a sentence S, derive the optimal dependency graph D for S according to M.
$\checkmark$ Traditional-based dependcy parsing
Transition-based dependency parsing relies on a state machine which defines the possible transitions to create the mapping from the input sentence to the dependency tree. The learning problem is to induce a model which can predict the next transition in the state machine based on the transition history. The parsing problem is to construct the optimal sequence of transitions for the input sentence, given the previously induced model. Most transition-based systems do not make use of a formal grammar.
$\checkmark$ Greedy Deterministic Transition-Based Parsing
$\checkmark$ Neural Dependency Parser