이전 시간까지 프로레서와 스레드, 그리고 동시성에 대해서 이야기했었습니다. 내용 중에 “원하는 연산은 CPU 프로세서로 가서 처리 된다.”라고 자주 CPU라는 녀석이 언급됐었는데, 오늘은 그 CPU, Central Processing Uni와 이 CPU가 명령어를 처리하기 위한 Schedule 에 대해서 다뤄볼까 합니다.
1. What is CPU(Central Processing Unit)?
- 본 챕터는 친절한 임베디드 시스템 개발자 되기 강좌에서 CPU관련 내용을 가져왔습니다.
CPU는 “컴퓨터 프로그램의 명령어를 처리하기 위한 논리회로의 집합을 담고 있는 핵심 부품”입니다.
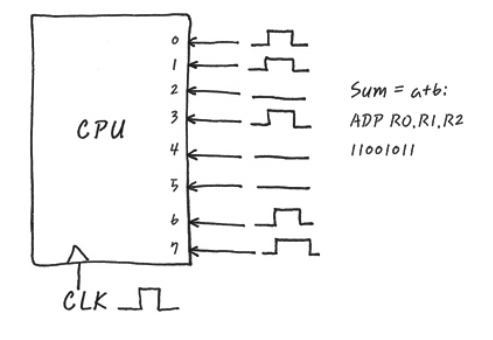
Reference. 확장 to the CPU - How CPU Works, http://recipes.egloos.com/4982160
예를 들어 a+b를 계산하고 싶으면 내부적으로 Register R1에 a가 Register R2에 b가 들어 있고 그 결과를 Register R0에 저장하는 매커니즘으로 동작하기위해 전기 신호로 $11010011_{2}$을 주면 CPU가 Register R1과 Register R2를 더해서 그 결과를 Register R0에 저장하는 것이죠.
이게 다 우리가 짜는 코드랑 어떻게 연결돼 있을까~? Designer. University of California, Berkeley
이 CPU에서 하는 명령어들은 어떤 게 있을까요? 위 그림은 Reduced Instruction Set Computer(RISC-V)에 속하는 CPU 중 하나의 Instruction입니다. 다 알필요는 없구요… 그냥 저렇게 많다는 걸 보여드리고 싶었습니다.
이러한 Instruction을 위해서 CPU는 기본적으로 제어장치 CU(Control Unit), 연산장치 ALU(Arithmetic Logic Unit), 그리고 CPU내부에 저장 공간인 Register 집합체가 있습니다. 이제 하나씩 역할을 살펴보죠, 천천히!
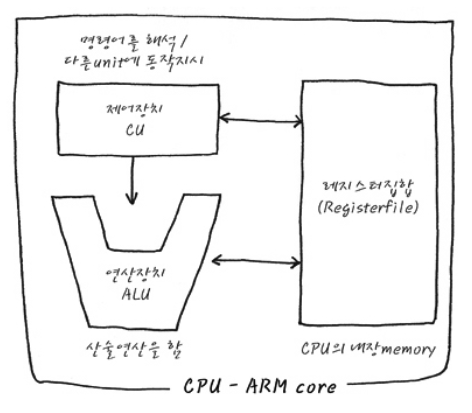
Reference. 확장 to the CPU - How CPU Works, http://recipes.egloos.com/4982160
1.1 Operation of CPU
그래도 CPU 동작을 이해하려면 간단한 예시가 필요하겠죠? 조금 더 자세하게 간소화된 CPU모델을 가져와 CPU 동작 과정을 살펴보죠.
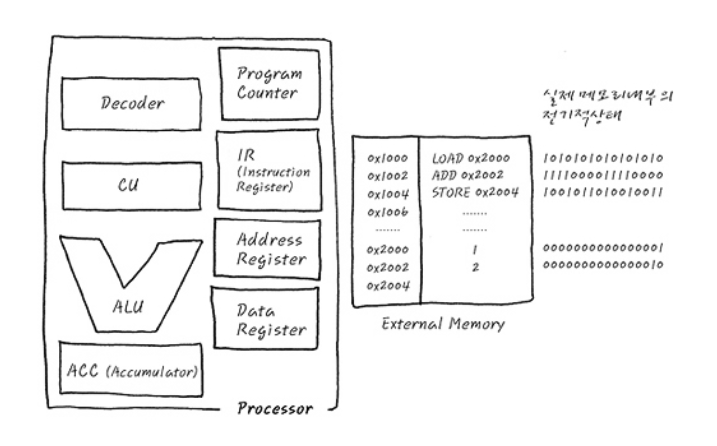
Reference. 일반적인 CPU 동작의 예와 Pipeline, http://recipes.egloos.com/4982160
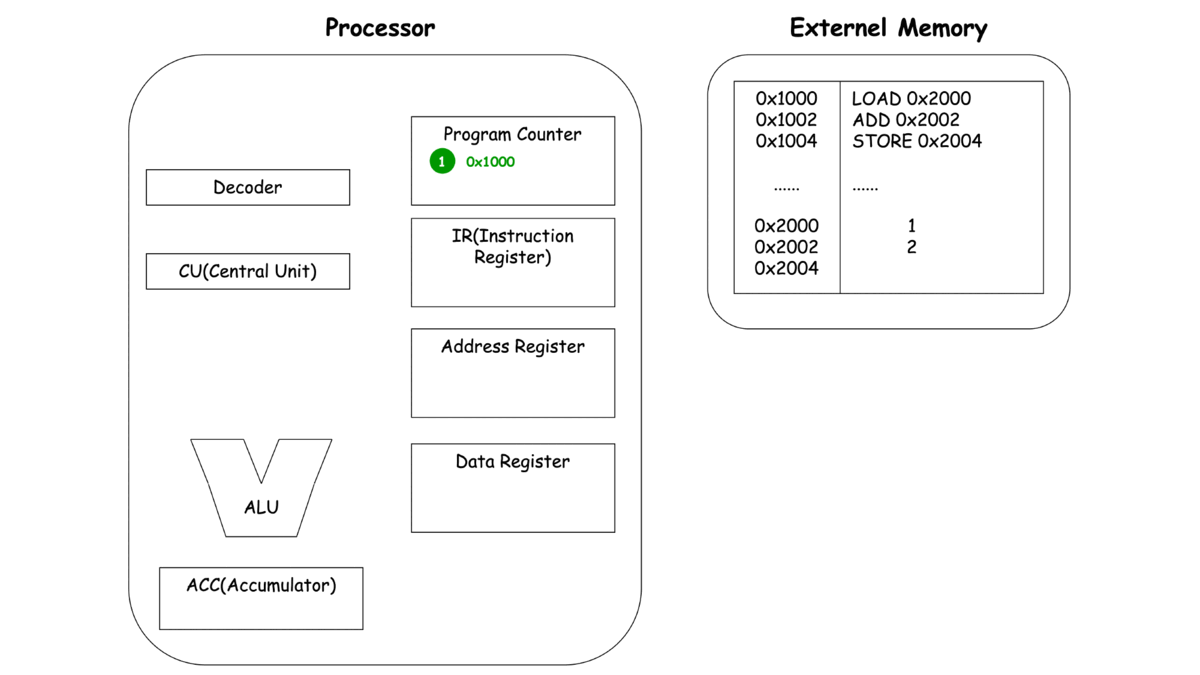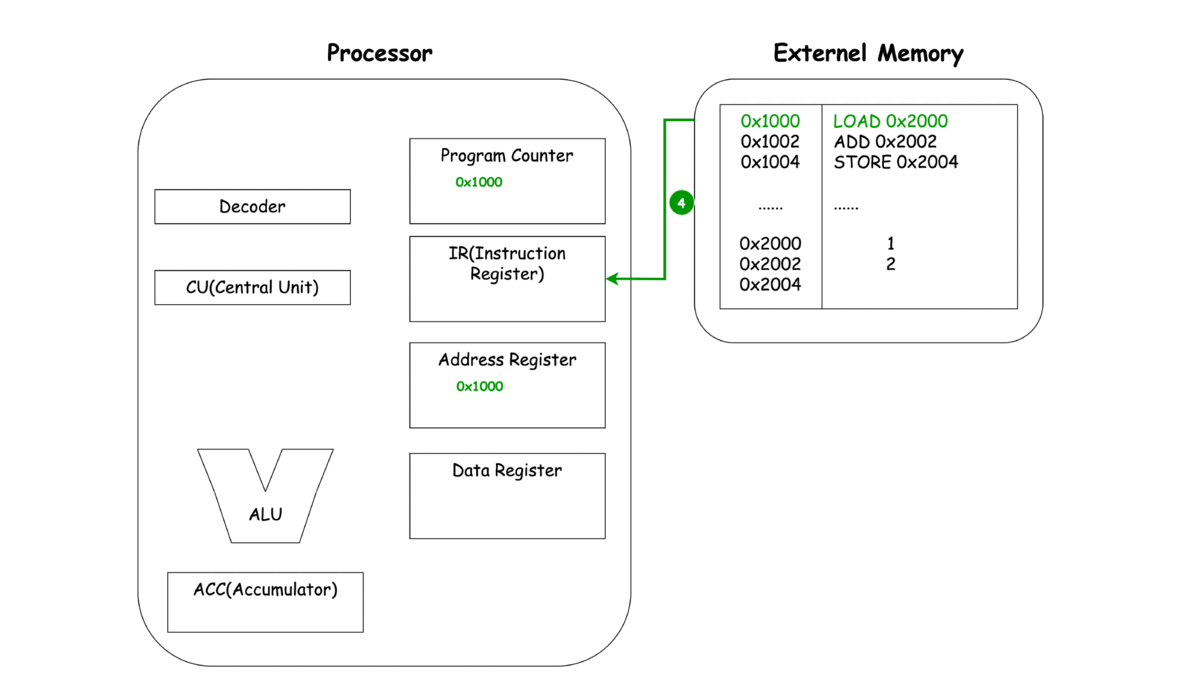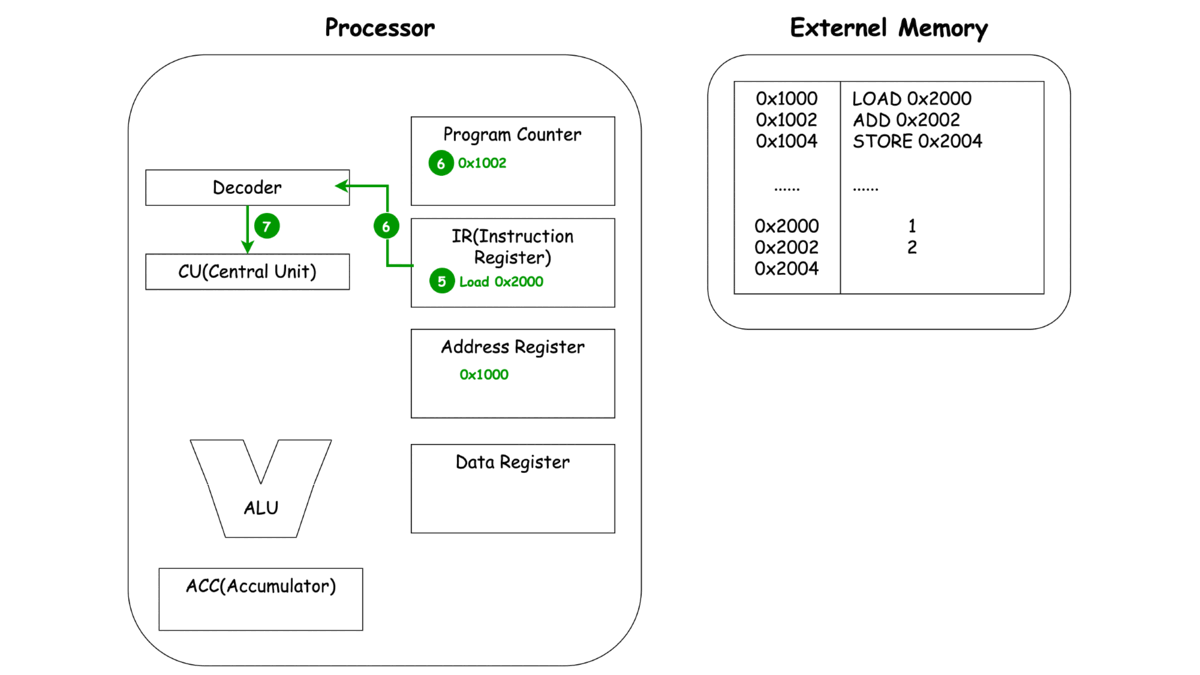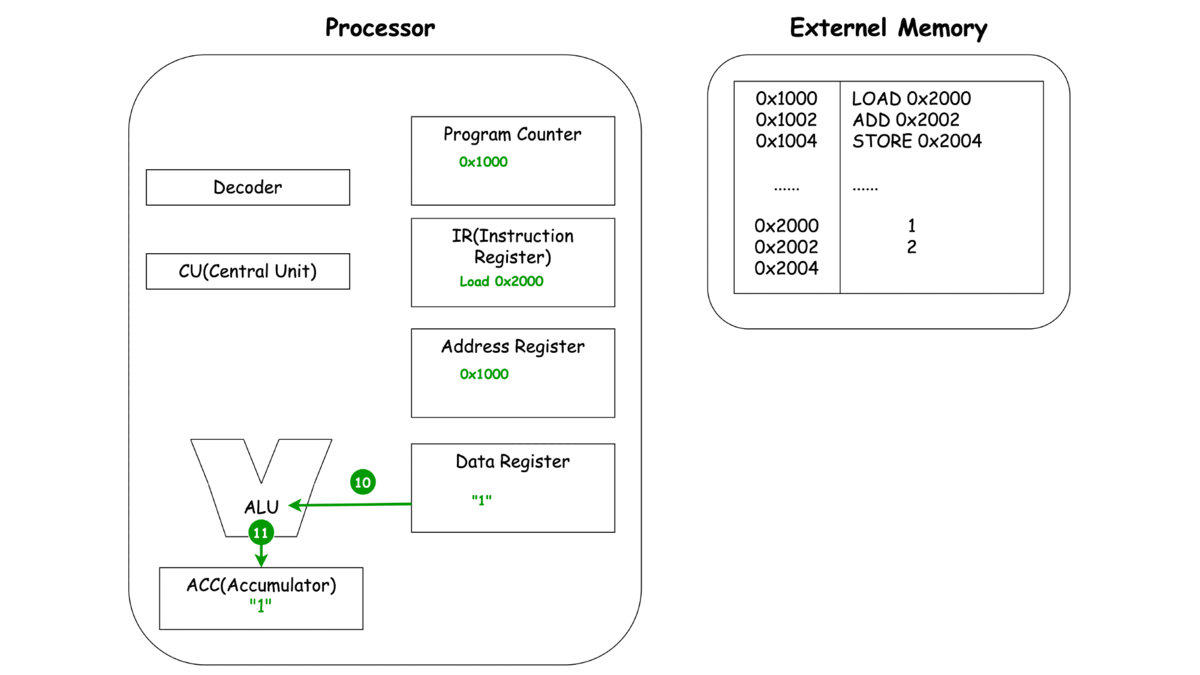
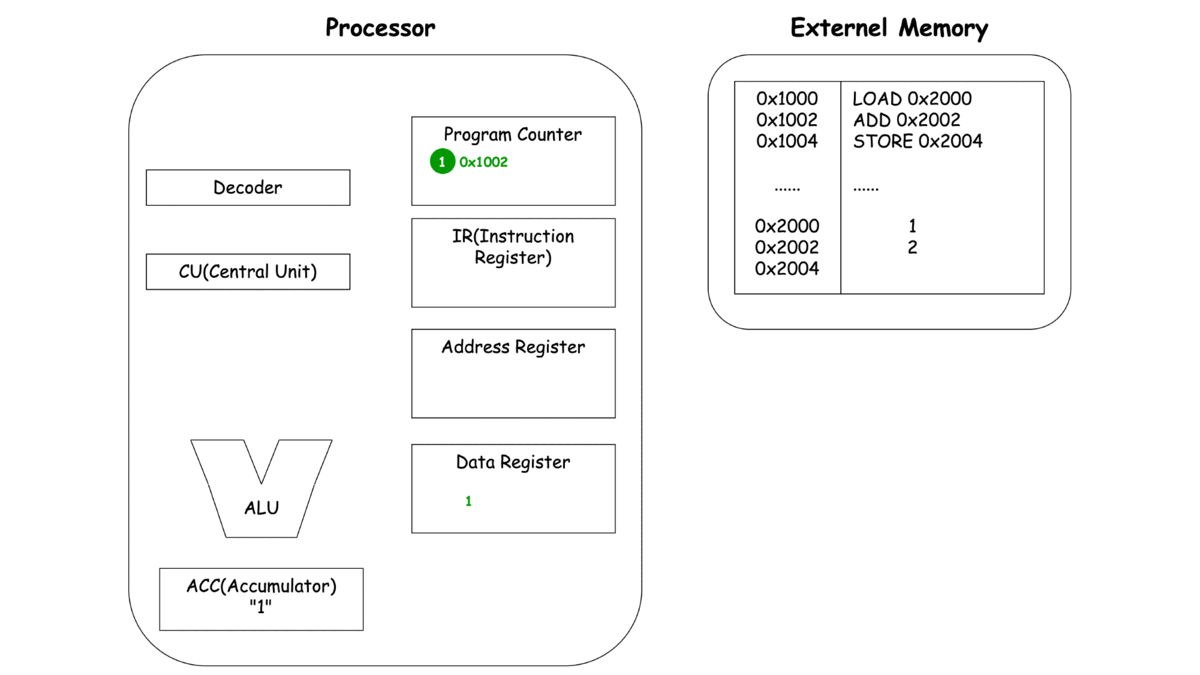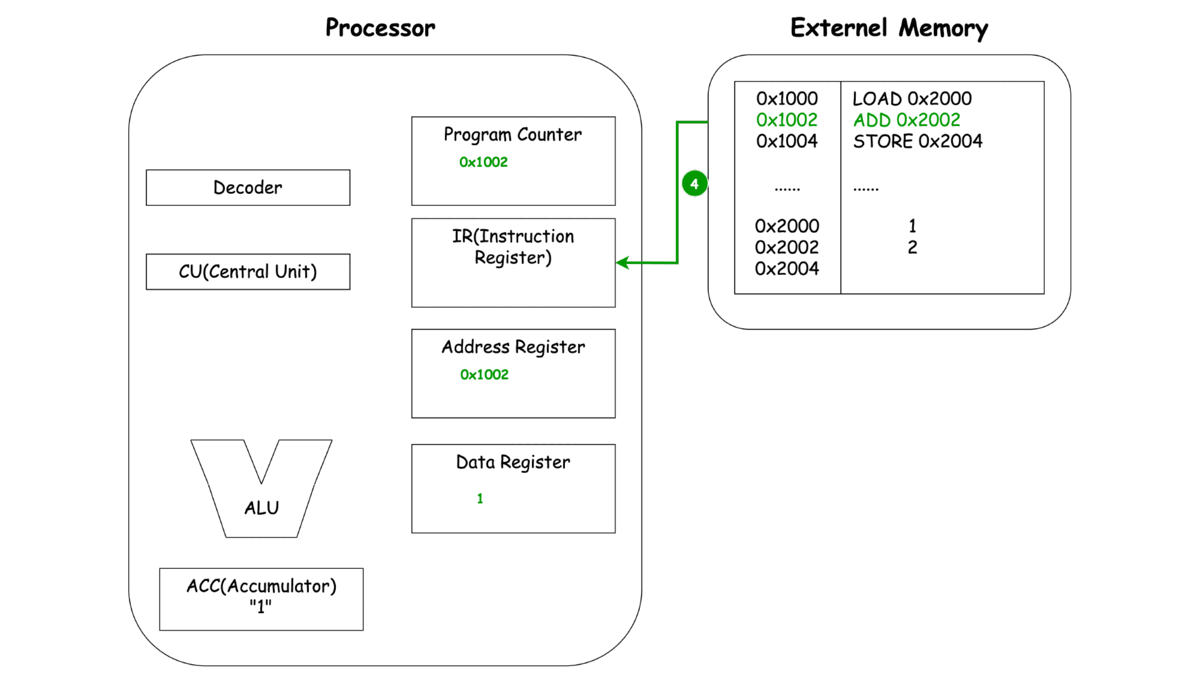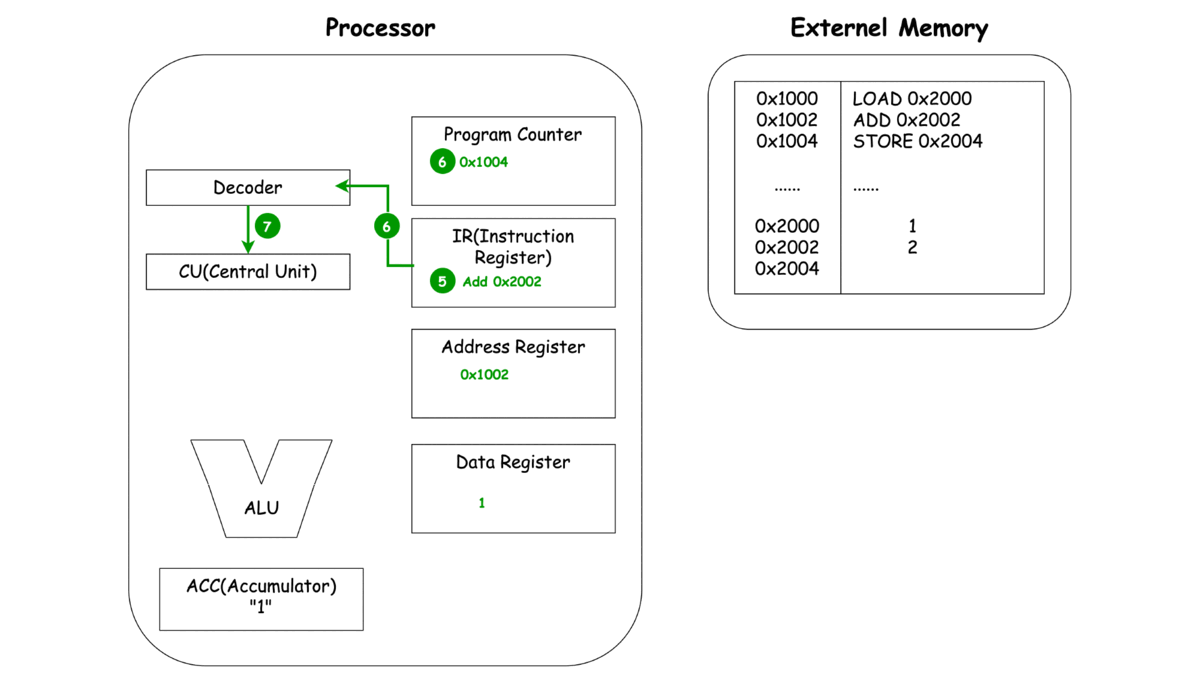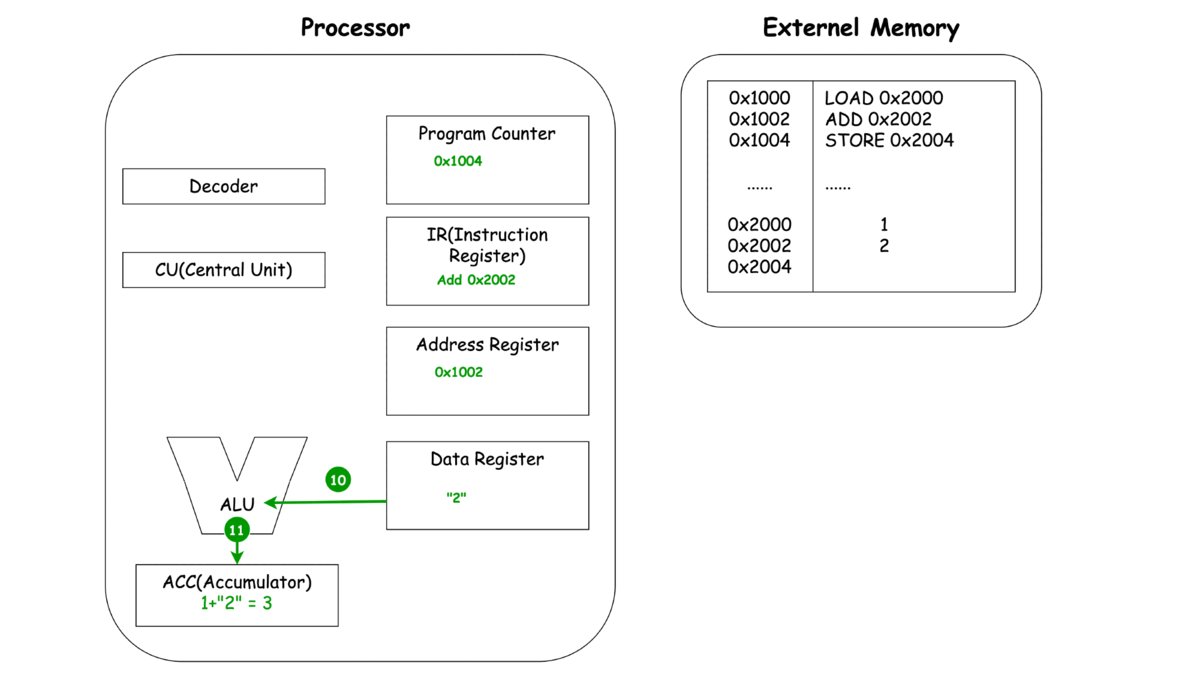
우선 안에 있는 Compnent를 한 번 보실까요?
- Register
- Program Counter(PC): CPU가 현재 실행하고 있는 Instruction의 주소를 가리킴
- Instruction Register(IR): PC가 가리키는 Instruction의 주소에서 읽어온 Instruction을 담아두는 기억장소
- Address Register: 현재 사용하는 Data를 access하기 위한 data의 주소를 가리키는 값을 담아두는 기억 장소
- Data Register: Address Register가 가리키는 주소의 실제 값
- Accumulator(ACC): 특수 Register, 연산에 사용되는 값들을 저장하며 연산의 결과값을 잠시 저장하는 일이 많음. 외부 사용자가 직접 Access를 할 수 있는 Register는 아니고 CPU가 독식함
- CPU Component
- Decoder: IR에서 가져온 Instruction을 해석해서 CU에 넘김
- Central Unit(CU): Decoder에서 받아온 각종 제어 신호를 변환하여 제어 신호를 발생시킴
- Arithmetic Logical Unit(ALU): 산술 연산 담당
1.2 Example
사실 저렇게 역할을 보고서, “아 그렇구나.” 하고 이해하기는 저는 어려웠습니다. 그래서 간단한 예를 들어 이해해보도록 하죠.
word a=1;
word b=2;
word c;
word add (void)
{
int temp;
temp = a;
c = a + b;
return;
}
간단한 코드입니다. Hello World를 출력할 줄 아신다면, 이 정도 코드를 많이 보셨을 텐데요. a, b, c는 전역변수고 절대 주소를 가지면서, CPU가 16bit processor, 1 word = 2byte라고 가정하고 그 절대 주소를 a는 0x2000, b는 0x2002, c는 0x2004로 임의로 할당해 보겠습니다.
이 때, 이 코드를 compile하면 다음과 같은 Assembly가 생성된다고 가정해보겠습니다.
주소 Assembly
0x1000 LOAD 0x2000
0x1002 ADD 0x2002
0x1004 STORE 0x2004
이제 각각의 동작마다 프로세서와 메모리에서 일어나는 과정을 한번 살펴보죠.
-
LOAD
-
ADD
-
STORE
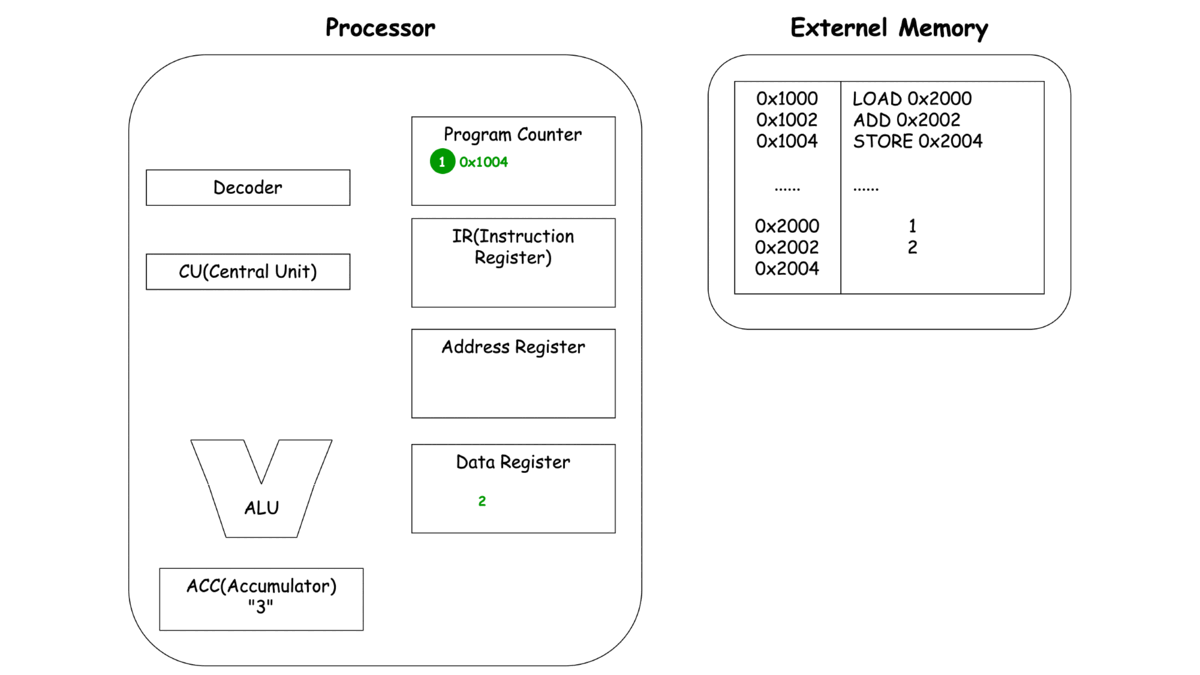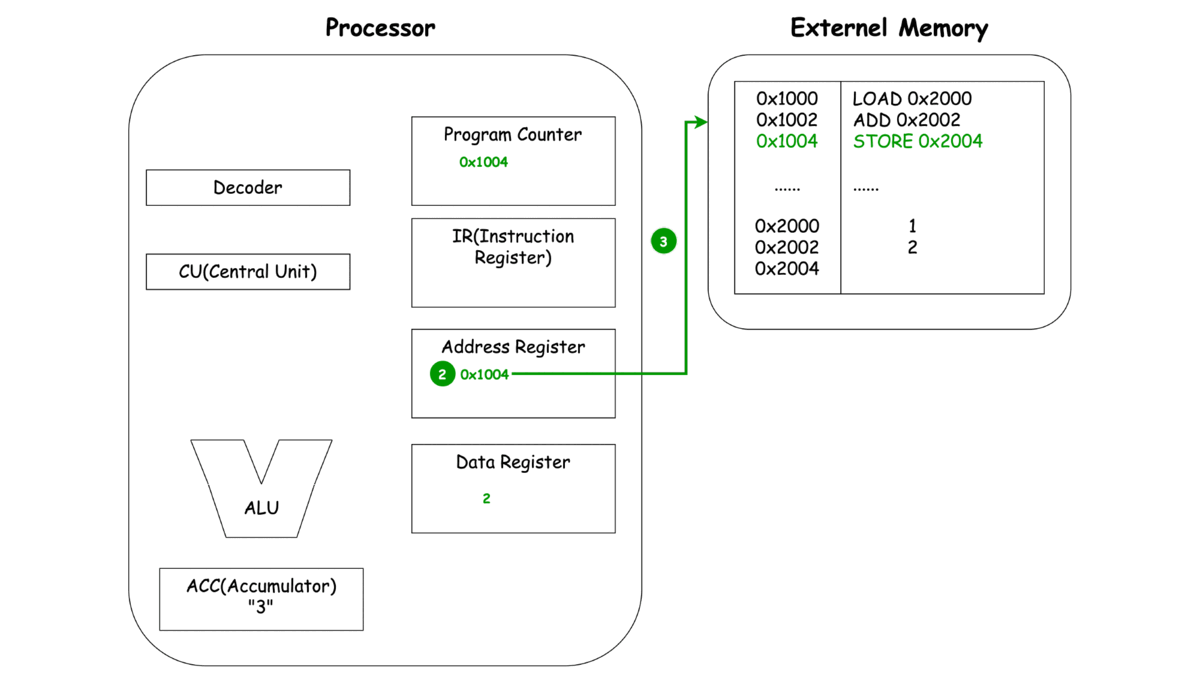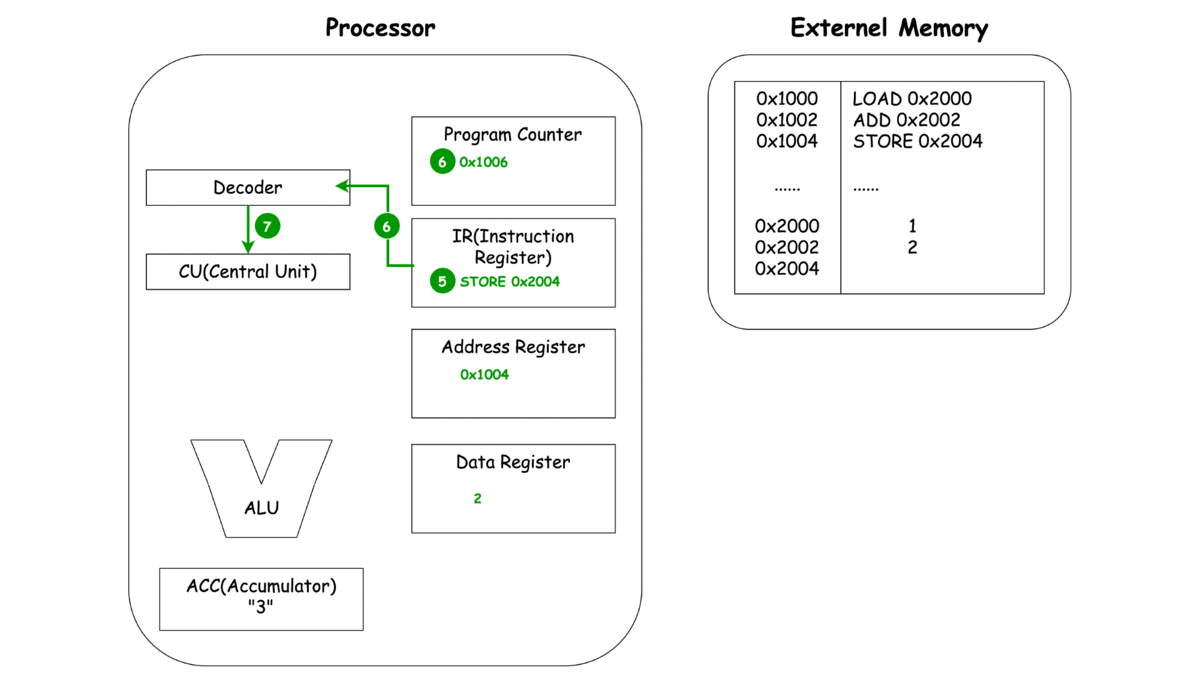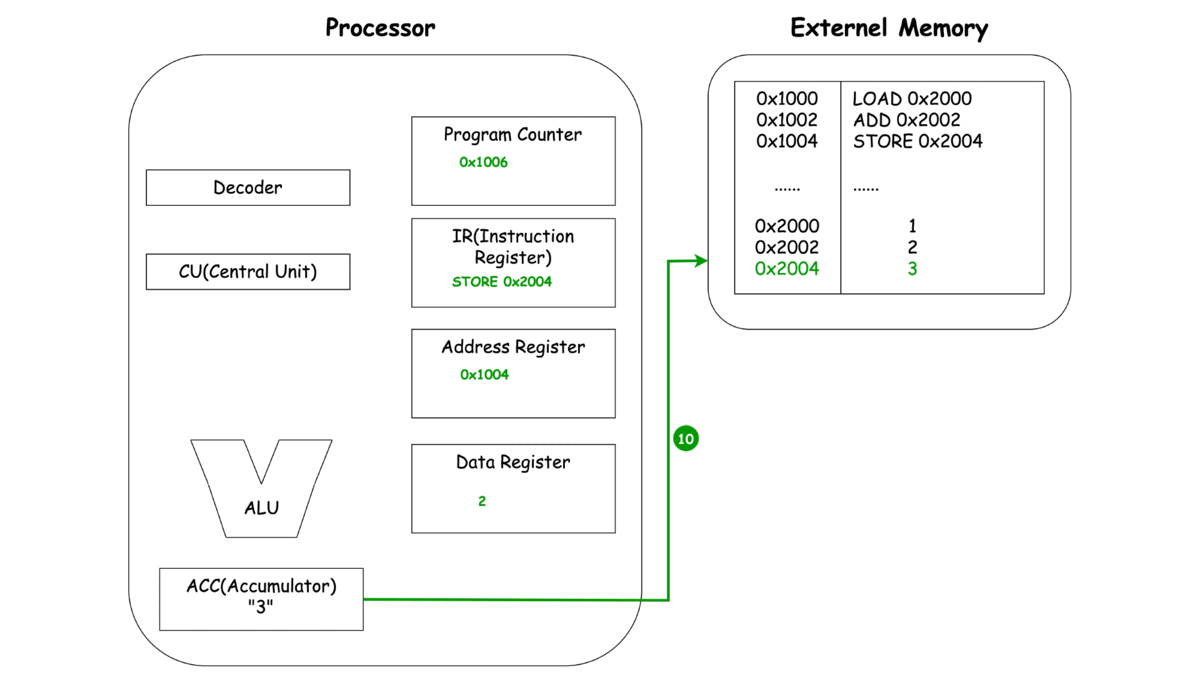
*본 과정은 여기 블로그에 자세하게 설명돼 있습니다.
이렇게 보는 CPU의 동작 LOAD, ADD, STORE에서 중복되는 부분이 보이지 않으시나요? 바로 세 가지 동작 Unit, 명령어를 메모리로 부터 가져오고(Fetch), 명령어를 해석하여 다른 Unit에 동작을 지시하고(Decode), 이렇게 가지는 명령어와 레지스터에 저장된 녀석들을 이용해 연산(Execute)으로 **나눌 수 있을 것 같네요.
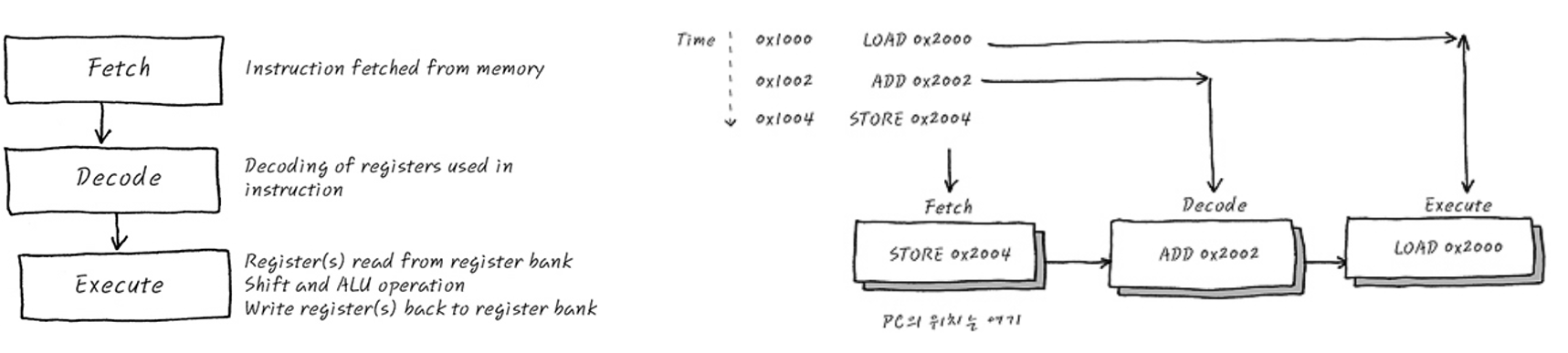
Reference. 일반적인 CPU 동작의 예와 Pipeline, http://recipes.egloos.com/4982160
그리고, Fetch/Decode/Excute 도 각각 쓰이는 레지스터가 다른 것으로 보아, 한번에 진행될 수 있을 것도 같네요. 더 자세한 내용은 생략하고, 궁금하면 여기 블로그에 자세하게 설명돼 있습니다.
여기서 보여준 CPU명령어는 LOAD, STORE, STORE였지만, 이 외에도 더하고 빼는 것은 물론이고 파일 저장하자(File system)! 네트워크로 보내자(I/O)! 외부장치에서 입력이 들어왔다(I/O)! 등 여러가지 경우가 있습니다. 자세한 디테일은 경우에 따라 해석하는 걸로,,,
1.3 Instruction, User mode vs Kernel mode
여기서도 특별한 CPU명령어가 있습니다. 바로 “Kernel mode”입니다. 예를 들어 Add, Sub, Jump는 저희가 쓰는 코드에서 자주 쓰는 User mode 명령어인데요. Kernel 모드는 Interrupt, setting page table와 같은 명령어를 위해서 만들어졌어요 (page table은 virtual address 를 physical address에 mapping하는 것:D).
말이 너무 어려운데, 간단히 개념적으로 하드웨어를 직접적으로 조작할 수 있는 명령어가 바로 커널모드 입니다(“privileged instructions”라고 부르기도 합니다. 하드웨어를 조작할 수 있는 특별한 녀석들이죠). 반대로 유저모드는 “unprivileged instructions”로 우리에게 익숙한 add, sub, jump, branch와 같은 명령어가 있습니다. 아까 프로세서 레지스터가 여럿 있었죠? 프로세서에서는 유저모드와 커널모드를 CPSR(Current Program Status Register)를 확인하고 어떤 모드인지 확인한답니다.
왜 그럼 유저모드와 커널모드 명령어로 나눌까요? 그리고 왜 알아야 할까요? 이전에 OS에서 언급했듯, 커널을 이용해서 하드웨어 리소스를 이용한다고 한 것이 바로 커널 모드 명령어를 사용하는 것입니다. 그렇기 때문에 User Application에서 하드웨어 리소스를 사용하기 위해서는 System Call Interface(SCI)를 이용해서 커널모드로 스위칭(Mode Switch)를 해서 아래와 같이 하드웨어에 접근하는 거죠. 아무래도 하드웨어까지 가는 길이 멀어보이죠?
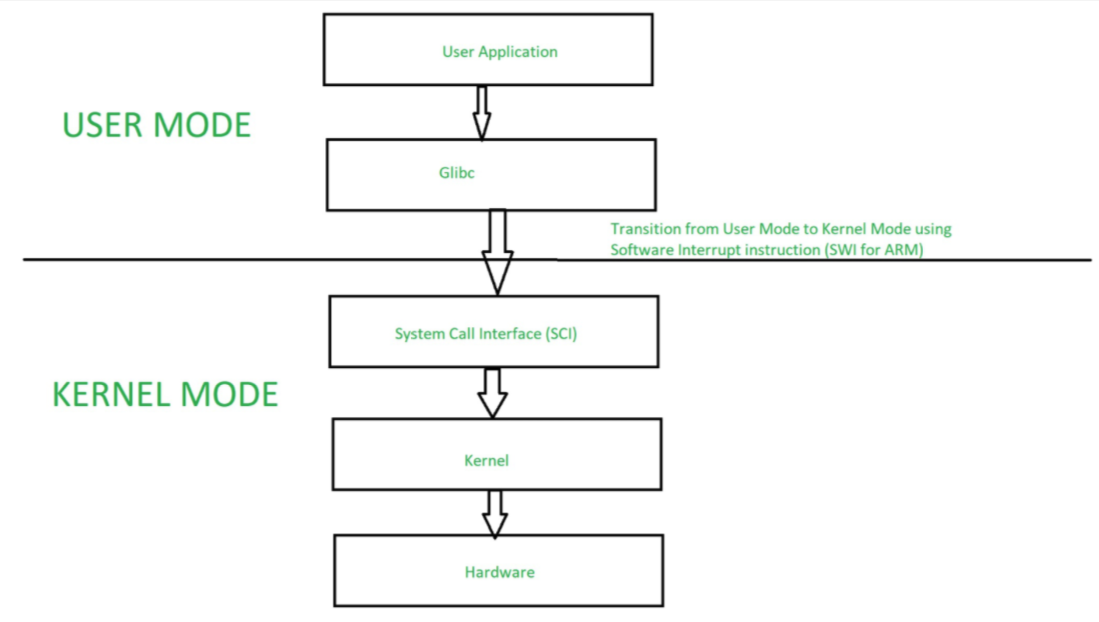
Reference. https://www.geeksforgeeks.org/user-mode-and-kernel-mode-switching
자세한 System Call Interfaces(SCI)의 예시는 하드웨어 구조에 따라 다른데, 종류가 참 많아서 링크를 첨부해둘게요. Java에서도 깊숙히 들어가면 있다니, 혹시 발견하면 제보 부탁드려요!
- x64 Linux system call table
- 예시: 주로 %rax에 특정 변수를 저장한 후 system call을 하면, 시스템 호출(system call)은 운영 체제의 커널이 제공하는 서비스에 대해, 응용 프로그램의 요청에 따라 커널에 접근하기 위한 인터페이스이다. 보통 C나 C++과 같은 High-level programming language로 작성된 프로그램들은 직접 시스템 호출을 사용할 수 없기 때문에 High-level API를 통해 시스템 호출에 접근하게 하는 방법이다.
1.4 Types of Processing Unit
이전에는 MCU, CPU, GPU 이렇게만 있던 프로세스의 종류가 아래처럼 종류가 다양하게 생겼습니다. 인공지능 덕분 일까요, 이건 참고로 알아두시면 좋을 것 같아서 정리해봤어요.
- MCU(Micro Controller Unit)
- GPU(Graphical processing Unit)
- NPU(Neural Processing Unit)
- TPU(Tensor Processing Unit)
- SPU(Sparse Processing Unit)
- EPU(Explainable Neuro-Processing Unit)
- IPU(Intelligence Processing Unit)
- BPU(Brain Processing Unit)
2. CPU Scheduler
이제 CPU가 하는 역할을 알았으니, 한 두개가 아닌 이 녀석들을 일을 빼곡하게 시키는 방법을 생각해보죠(그럴려고 만든 거니까요). 이를 스케줄링(CPU Scheduling)이라고 하는데요, “CPU가 놀지 않도록 Process를 선택하는 역할”을 합니다.
2.1 CPU and I/O Burst Cycle
아직, 스케줄러 전에 개념을 하나 더 짚고 넘어가야 합니다. 별건 아니고, “Burst Cycle” 입니다. CPU나 I/O와 같은 작업시에 소요되는 CPU 처리하는 연산 횟수입니다.
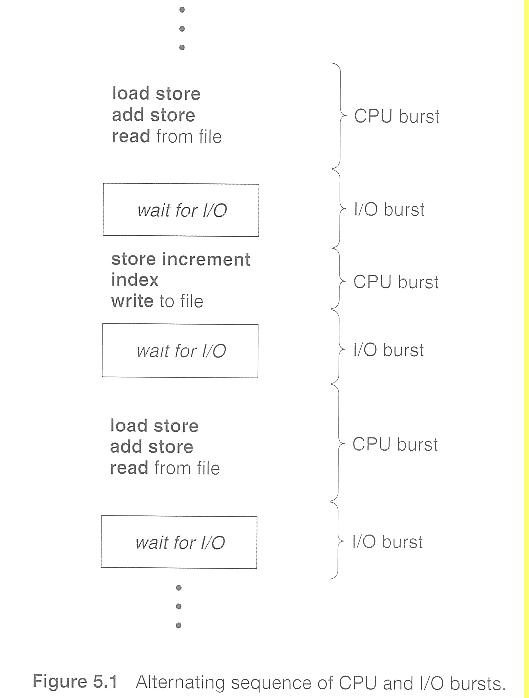
Reference. Operating Systems 5 CPU Scheduling in UIC
CPU burst경우 프로세스 마다, 프로그램마다 burst 시간이 다르게 분포한다고 하네요. 아래의 그림은 CPU burst 시간에 대한 빈도수(Frequency) 분포입니다.
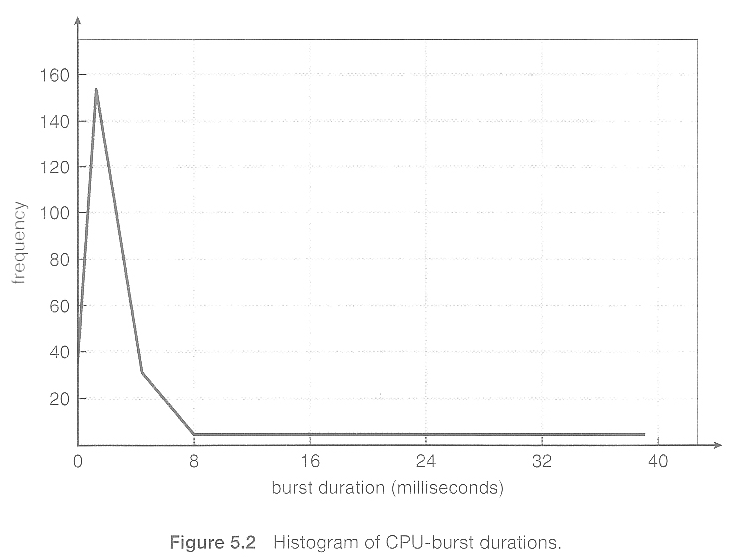
Reference. Operating Systems 5 CPU Scheduling in UIC
2.2 Type of CPU Scheduler
자, 그러면 이제 준비는 다했고, CPU 스케줄러를 이야기 할 차례입니다. CPU Scheduler는 기본적으로 CPU가 idle상태(쉰다)의 경우 다른 프로세스를 ready queue에서 run상태로 가져옵니다. 이 스케줄러의 방식에는 크게 선점형(Preemtive)과 비선점형(Non-Preemtive)이 있습니다. 아래와 같이 CPU가 상태가 변할 때, 선점형은 다른 작업이 치고 들어갈 수 있다를 의미하고 비선점형은 CPU에서 시작한 작업은 꼭 끝날 때까지 기다려야하는 것을 말합니다. 그럼, 비선점형은 참 느리겠죠?
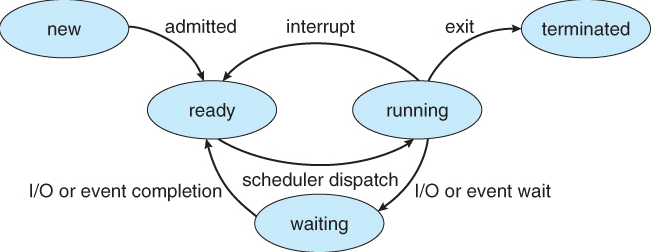
Reference. Operating Systems 5 CPU Scheduling in UIC
-
Preemtive scheduling(선점)
CPU에서 작업이 끝나지 않았는데 새로운 작업이 들어 갈 수 있는 스케줄링
-
Non-Preemtive scheduling(비선점)
CPU에서 작업이 끝나기 전까지는 새로운 작업이 못들어가는 스케줄링
자원을 점유하냐, 하지 않냐로 나뉘는 CPU Scheduler, 이 개념에서 종종 Dispatcher라고 이름이 나오곤 합니다. 이 녀석은 위에 그림에서 처럼 Scheduler에 의해서 Ready상태의 프로세스를 Running 상태로 바꿔주죠? 그러면 프로세스에서 배웠던 것처럼 프로세스를 바꿔줄 때 Context Switching을 하고 만약 이전에 프로세서가 무슨 일을 처리하다가 빠졌던 경우라면 프로세서를 적절한 위치로 이동시켜줘야 겠죠? 그리고 프로세스를 Kernel Mode에서 User Mode로 바꿔줍니다(하드웨어 조작이 아니라 SAVE, LOAD와 같은 CPU Burst라서 User Mode로 바꿔주는 걸까요?).
What is Dispatcher ?
- 선택된 프로세서에게 CPU를 할당하는 역할
- Context Switch
- Kernel mode → User mode
- 프로세서를 적절한 위치로 이동
그럼 어떤 CPU Scheduling 알고리즘이 있을까요? 알고리즘에 앞서 이를 비교평가하려면 지표들이 필요하겠죠.
2.3 Scheduling Criteria
지표는 총 5가지가 있습니다. 천천히 읽어보시죠!
- Arrival Time: Time at which the process arrives in the ready queue.
- Completion Time: Time at which process completes its execution.
- Burst Time: Time required by a process for CPU execution.
-
Turn Around Time: Time Difference between completion time and arrival time.
Turn Around Time = Completion Time – Arrival Time -
Waiting Time(W.T): Time Difference between turn around time and burst time.
Waiting Time = Turn Around Time – Burst Time
CPU가 Running을 끝낸다고 작업이 끝나지 않는 경우도 있어, 경우가 여러가지로 나뉜 것으로 보입니다 (예를 들어 잠시 Waiting으로 빠진다던지, 선점형 스케줄러를 사용했다던지). 그럼 이제 알고리즘으로 들어가 보시죠.
2.4 CPU Scheduling Algorithm
-
First-Come, First-Served (FCFS) Scheduling
“먼저 오면 먼저 처리!” 첫번째 방식은 간단하게 먼저 도착하면, 먼저 처리하는 방식입니다. 그러면 만약 시스템이 dynamic하게 있다면 CPU burst가 긴 프로세스가 먼저 오게되면 뒤에 프로세스들은 기다려야 겠군요.
이 경우 예제를 들어 보면,
Process Burst Time (ms) P1 24 P2 3 P3 3 이 프로세스는 “average waiting time” 을 구해보면 두 가지 경우에 따라 결과가 달라집니다.
- P1 → P2 → P3 = (0 + 24 + 27)/3 = 17.0 ms
- P2 → P3 → P1 = (0 + 3 + 6)/3 = 3.0 ms
누가 먼저 오느냐에 다라 프로세스가 대기하는 시간이 달라지는군요!
*왜 average waiting time을 구하냐구요? 다른 작업들이 가장 적은 시간을 기다리는 게 멀티 테스킹(Multi-tasking)에서 중요하지 않을까요? 멀티 테스킹이 궁금하다면 여기로!
-
Shortest-job-first(SJF) Scheduling
두번 째 방식은 “프로세스의 다음 CPU burst가 가장 짧은 순서” 그럼 현 시점에 Ready Queue에 있는 프로세스들 중에 CPU Burst가 짧은 녀석들 부터 처리해 보죠. Shortest-job-first 방식입니다. 이 경우는 그럼 프로세스를 처리하는데 가장 빠를 것 같죠.
예를 들어 아래와 같이 프로세스가 있다고 해보죠.
Process Burst Time (ms) P1 6 P2 8 P3 7 P4 3 위 예시의 경우 P4 → P1 → P3 → P2 순으로 프로세스를 처리하겠죠? 그럼 Average wait time은 (0+3 +9+16) / 4 = 7.0 ms가 됩니다.
그런데 어떤 문제가 있을 수 있을까요? 만약 짧은 프로세스가 빈번하게 있다고 가정합시다. 그러면 오래 걸리는 프로세스 같은 경우는 한도 끝도 없이 기다리겠네요. 그리고 과연 실무에서 짧은 CPU burst의 프로세스만 들어 올 수 있을까요?
음…그럼 만약에 다음 프로세스가 오기전에 예상해보는 건 어떨까요? 예측한 시간이 길면 거기에 맞게 또 스케줄링을 할 수 있지 않을까요? 한 가지 예측하는 이론으로 나온 것은 “Exponetial average”이 있습니다. 정의는 아래와 같은데요.
\[estimate[i+1] = alpha*burst[i]*(1.0-alpha)*estimate[i]\]이 방법을 따르면 CPU burst에 따라 다음 시간을 예측해 볼 수 있죠, 아래와 같이 말이에요.
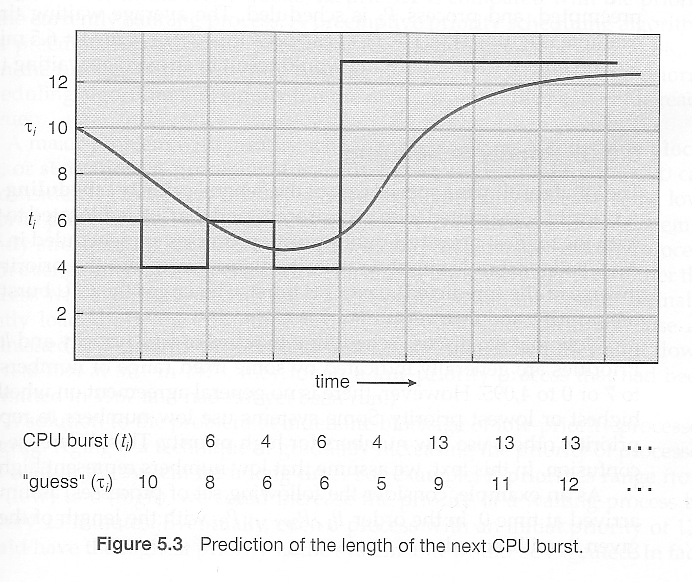
Reference. Operating Systems 5 CPU Scheduling in UIC
예측시간은 여기까지 하고, 구체적으로 예시로 들어가보죠. 우선 SJF도 Preemptive와 Non-preemptive로 나눌 수 있습니다. 참고로 Preemptive SJF는 “shortest remaining time first scheduling이라고 부르기도 합니다. 예시로 가볼까요?
Process Arrival Time Burst Time (ms) P1 0 8 P2 1 4 P3 2 9 P4 3 5 만약 Preemptive SJF로 한다면 이 경우 프로세스는 P1 → P2 → P4 → P1 → P3 이렇게 처리할 테니, 각 프로세스의 waiting time으
P1 = 10-1 P2 = 0 P3 = 17-2 P4 = 5-3로 average wait time은 ((5-3) + (10-1) + (17-2))/4 = 6.5ms 가 되겠네요. 반면에 다른 알고리즘을 계산해보면 Non-preemptive SJF는 7.75ms, FCFS는 8.75ms가 걸립니다.
-
SRTF(Shortest-Remaining-Time-First) Scheduling
“남은 CPU burst가 가장 짧은 프로세스부터 실행” 이전에 SJF에서 설명했으니 패스!
-
Priority Scheduling
“우선순위가 높은 프로세스부터 실행” 이 알고리즘은 말 그래도 Priority입니다. 예제를 들어보죠
Process Priority Burst Time (ms) P1 3 10 P2 1 1 P3 4 2 P4 5 1 P5 2 5 그러면 프로세스는 P2 → P5 → P1 → P3 →P4 순으로 처리되겠네요. 아, Priority는 여기서는 숫자가 낮을 수록 높습니다. 그러면 average waiting time은 8.2 ms가 됩니다.
Priority를 그럼 어떻게 둘 수 있을 까요? 이 경우는 “Internally” 와 “Externally”로 구분지을 수 있겠죠. Externel은 유저에 의해서 정하면 될 거구요, Internel은 OS에서 average burst time, ratio of CPI to I/O activity, system resource use, 그리고 커널에서 이용가능한 여러가지 요소들에 의해서 정해진다고 하네요. 주체가 유저냐, OS냐의 차이겠죠.
Priority 스케줄링 알고리즘 또한 Preemptive vs Non-preemptive로 나눌 수 있습니다. 그런데 이 스케줄링은 낮은 Priority를 가진 프로세스는 높은 Priority가 있는 프로세스가 줄지어 온다면, 계속 기다려야 겠네요. 이 문제를 “indefinite blocking or starvation” 이라고 부릅니다. 그럼 어떻게 해결해야 되요? 너무 오래 기다린 친구들의 Priority를 올려주는 “aging”가 있습니다.
-
Round-Robin(RR) Scheduling
“time slice로 나눠진 CPU time을 번갈아가며 실행” 다섯 번째 스케줄링 알고리즘은 제한시간을 두자! 입니다. 이 제한시간을 time quantum이라고 부르기도 하는데요, 어디서 많이 들어 봤죠? Multi-tasking입니다. 이 알고리즘의 경우는 다음과 같을 수 있어요.
- time quantum내에 프로세스가 끝난 경우: FCFS scheduling
- time quantum내에 프로세스가 끝나지 못한 경우: ready queue 맨뒤로 들어간다.
- ready queue는 circular queue로 구성한다.
그럼 예시를 들어볼까요?
Process Burst Time (ms) P1 24 P2 8 P3 3 time quantum을 4ms로 뒀다고 가정해보죠. 그럼 프로세스의 순서는 P1 → P2 → P3 → P1이 되고 averaging wait time은 (4+7+(10-4))/3 = 5.66ms가 될겁니다.
이 스케줄링은 역시 — time quantum에 sensitivie할 겁니다. time quantum이 작으면 CPU에게 모든 프로세스가 균등하게 분배되겠지만, context switching비용이 어마어마 하겠죠. 여기서는 요즘 시스템들은 10-100 ms 로 time quantum를 두고 context switch time은 10us정도여서 overhead가 상대적으로 작다고 하네요.
-
Multilevel queue Scheduling
“프로세스들을 그룹화해서 그룹마다 큐를 두는 방식” 프로세스들을 그룹화해서 여러개의 분리된 큐로 관리하는 방식이 Multilevel queue Scheduling 입니다. 예시를 아래와 같이 볼 수 있겠네요.
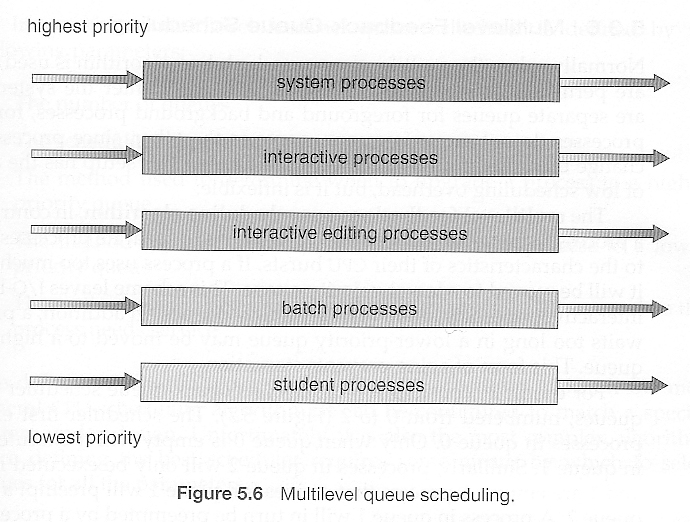
Reference. Operating Systems 5 CPU Scheduling in UIC
-
Multilevel Feedback-Queue Scheduling
마지막으로 소개할 Scheduling은 “Level”에 따라 queue를 두는 방법이에요. 예시를 보면 더 이해하기 쉬울 것 같네요.
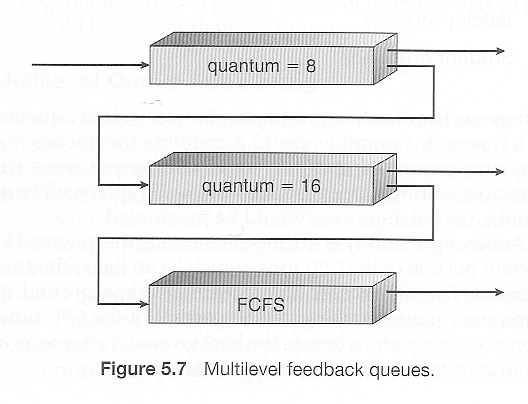
Reference. Operating Systems 5 CPU Scheduling in UIC
처음 queue에서 다음 queue로, 그 다음 queue로 프로세스가 넘어가거나, 처리되거나가 보이시죠. 다음 level로 넘어갈 수 있는 이유에는 여럿이 있을 텐데요.
- 만약 CPU-intensive 작업에서 I/O-intensive 작업으로 바뀌는 경우
- Aging의 경우
외에도 어떤 경우가 더 있을 수 있을까요? flexible한 이 알고리즘은 queue의 수이며, 각 queue마다 scheduling하는 방법이며 다양하게 적용가능하겠네요.
여기까지 CPU의 동작원리에서부터 그 CPU를 Scheduling하는 알고리즘까지 살펴봤습니다
*외에 참조한 강의에서는 Threading schduling과 Multi-processing scheduling에 대해서도 언급하는데, 이건 추후에 추가해보도록 할게요.
3. TODO
Thread Scheduling, Multiple-Processor Scheduling, Operating System Examples
4. Reference
- User mode vs Kernel mode: https://www.geeksforgeeks.org/user-mode-and-kernel-mode-switching/
- How CPU Works: http://recipes.egloos.com/4982160
- 일반적인 CPU 동작 예시와 Pipeline: http://recipes.egloos.com/4982170
- CPU Sceduling in Operation Systems: https://www.geeksforgeeks.org/cpu-scheduling-in-operating-systems/
- Operating Systems 5 CPU Scheduling in UIC: https://www.cs.uic.edu/~jbell/CourseNotes/OperatingSystems/5_CPU_Scheduling.html
- CPU Scheduling Web visualization: https://github.com/Robertof/cpu-scheduling-web
- CPU 스케줄러와 Dispatcher, Scheduling 알고리즘: https://www.youtube.com/watch?v=LgEY4ghpTJI
- 성윤님의 CPU Scheduling과 Process: https://zzsza.github.io/development/2018/07/29/cpu-scheduling-and-process/